Cours 4 - Objets Kubernetes - Partie 1
L’API et les Objets Kubernetes
Utiliser Kubernetes consiste à déclarer des objets grâce à l’API Kubernetes pour décrire l’état souhaité d’un cluster : quelles applications ou autres processus exécuter, quelles images elles utilisent, le nombre de replicas, les ressources réseau et disque que vous mettez à disposition, etc.
On définit des objets généralement via l’interface en ligne de commande et kubectl de deux façons :
- en lançant une commande
kubectl run <conteneur> ...,kubectl expose ... - en décrivant un objet dans un fichier YAML ou JSON et en le passant au client
kubectl apply -f monpod.yml
Vous pouvez également écrire des programmes qui utilisent directement l’API Kubernetes pour interagir avec le cluster et définir ou modifier l’état souhaité. Kubernetes est complètement automatisable !
La commande apply
Kubernetes encourage le principe de l’infrastructure-as-code : il est recommandé d’utiliser une description YAML et versionnée des objets et configurations Kubernetes plutôt que la CLI.
Pour cela la commande de base est kubectl apply -f object.yaml.
La commande inverse kubectl delete -f object.yaml permet de détruire un objet précédement appliqué dans le cluster à partir de sa description.
Lorsqu’on vient d’appliquer une description on peut l’afficher dans le terminal avec kubectl apply -f myobj.yaml view-last-applied
Globalement Kubernetes garde un historique de toutes les transformations des objets : on peut explorer, par exemple avec la commande kubectl rollout history deployment.
Syntaxe de base d’une description YAML Kubernetes
Les description YAML permettent de décrire de façon lisible et manipulable de nombreuses caractéristiques des ressources Kubernetes (un peu comme un Compose file par rapport à la CLI Docker).
Exemples
Création d’un service simple :
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
ports:
- port: 443
targetPort: 8443
selector:
k8s-app: kubernetes-dashboard
type: NodePort
Création d’un “compte utiliseur” ServiceAccount
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
Remarques de syntaxe :
-
Toutes les descriptions doivent commencer par spécifier la version d’API (minimale) selon laquelle les objets sont censés être créés
-
Il faut également préciser le type d’objet avec
kind -
Le nom dans
metadata:\n name: valueest également obligatoire. -
On rajoute généralement une description longue démarrant par
spec:
Description de plusieurs ressources
-
On peut mettre plusieurs ressources à la suite dans un fichier k8s : cela permet de décrire une installation complexe en un seul fichier
- par exemple le dashboard Kubernetes https://github.com/kubernetes/dashboard/blob/master/aio/deploy/recommended.yaml
-
L’ordre n’importe pas car les ressources sont décrites déclarativement c’est-à-dire que:
- Les dépendances entre les ressources sont déclarées
- Le control plane de Kubernetes se charge de planifier l’ordre correct de création en fonction des dépendances (pods avant le déploiement, rôle avec l’utilisateur lié au rôle)
- On préfère cependant les mettre dans un ordre logique pour que les humains puissent les lire.
-
On peut sauter des lignes dans le YAML et rendre plus lisible les descriptions
-
On sépare les différents objets par
---
Objets de base
Les namespaces
Tous les objets Kubernetes sont rangés dans différents espaces de travail isolés appelés namespaces.
Cette isolation permet 3 choses :
- ne voir que ce qui concerne une tâche particulière (ne réfléchir que sur une seule chose lorsqu’on opère sur un cluster)
- créer des limites de ressources (CPU, RAM, etc.) pour le namespace
- définir des rôles et permissions sur le namespace qui s’appliquent à toutes les ressources à l’intérieur.
Lorsqu’on lit ou créé des objets sans préciser le namespace, ces objets sont liés au namespace default.
Pour utiliser un namespace autre que default avec kubectl il faut :
- le préciser avec l’option
-n:kubectl get pods -n kube-system - créer une nouvelle configuration dans la kubeconfig pour changer le namespace par defaut.
Kubernetes gère lui-même ses composants internes sous forme de pods et services.
- Si vous ne trouvez pas un objet, essayez de lancer la commande kubectl avec l’option
-Aou--all-namespaces
Les Pods
Un Pod est l’unité d’exécution de base d’une application Kubernetes que vous créez ou déployez. Un Pod représente des process en cours d’exécution dans votre Cluster.
Un Pod encapsule un conteneur (ou souvent plusieurs conteneurs), des ressources de stockage, une IP réseau unique, et des options qui contrôlent comment le ou les conteneurs doivent s’exécuter (ex: restart policy). Cette collection de conteneurs et volumes tournent dans le même environnement d’exécution mais les processus sont isolés.
Un Pod représente une unité de déploiement : un petit nombre de conteneurs qui sont étroitement liés et qui partagent :
- les mêmes ressources de calcul
- des volumes communs
- la même IP donc le même nom de domaine
- peuvent se parler sur localhost
- peuvent se parler en IPC
- ont un nom différent et des logs différents
Chaque Pod est destiné à exécuter une instance unique d’un workload donné. Si vous désirez mettre à l’échelle votre workload, vous devez multiplier le nombre de Pods.
Pour plus de détail sur la philosophie des pods, vous pouvez consulter ce bon article.
Kubernetes fournit un ensemble de commande pour débugger des conteneurs :
kubectl logs <pod-name> -c <conteneur_name>(le nom du conteneur est inutile si un seul)kubectl exec -it <pod-name> -c <conteneur_name> -- bashkubectl attach -it <pod-name>
Enfin, pour debugger la sortie réseau d’un programme on peut rapidement forwarder un port depuis un pods vers l’extérieur du cluster :
kubectl port-forward <pod-name> <port_interne>:<port_externe>- C’est une commande de debug seulement : pour exposer correctement des processus k8s, il faut créer un service, par exemple avec
NodePort.
Pour copier un fichier dans un pod on peut utiliser: kubectl cp <pod-name>:</path/to/remote/file> </path/to/local/file>
Pour monitorer rapidement les ressources consommées par un ensemble de processus il existe les commande kubectl top nodes et kubectl top pods
Un manifeste de Pod
kuard-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: nom_pod
spec:
containers:
- image: tecpi/pod_image:0.1
name: nom_conteneur
ports:
- containerPort: 8080
name: http
protocol: TCP
Les ReplicaSet
Un ReplicaSet ou rs est une ressource qui permet de spécifier finement le nombre de réplication d’un pod à un moment donné.
kubectl get rspour afficher la liste des replicas.
En général on ne les manipule pas directement.
Les Deployments
Plutôt que d’utiliser les replicasets il est recommander d’utiliser un objet de plus haut niveau : les deployments.
De la même façon que les ReplicaSets gèrent les pods, les Deployments gèrent les ReplicaSet.
Un déploiement sert surtout à gérer le déploiement d’une nouvelle version d’un pod.
Un deployment est un peu l’équivalent d’un service docker : il demande la création d’un ensemble de Pods désignés par une étiquette label.
Exemple :
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
strategy:
type: Recreate
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
-
Pour les afficher :
kubectl get deployments -
La commande
kubectl runsert à créer un deployment à partir d’un modèle. Il vaut mieux utilisezapply -f.
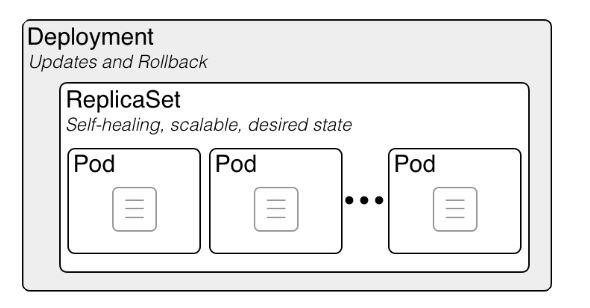 Les poupées russes Kubernetes : un Deployment contient un ReplicaSet, qui contient des Pods, qui contiennent des conteneurs
Les poupées russes Kubernetes : un Deployment contient un ReplicaSet, qui contient des Pods, qui contiennent des conteneurs
Les Services
Dans Kubernetes, un service est un objet qui :
- rassemble un ensemble de pods (grâce à des tags)
- et configure une politique permettant d’y accéder depuis l’intérieur ou l’extérieur du cluster.
L’ensemble des pods ciblés par un service est déterminé par un selector.
Par exemple, considérons un backend de traitement d’image (stateless, c’est-à-dire ici sans base de données) qui s’exécute avec 3 replicas. Ces replicas sont interchangeables et les frontends ne se soucient pas du backend qu’ils utilisent. Bien que les pods réels qui composent l’ensemble backend puissent changer, les clients frontends ne devraient pas avoir besoin de le savoir, pas plus qu’ils ne doivent suivre eux-mêmes l’état de l’ensemble des backends.
L’abstraction du service permet ce découplage : les clients frontend s’addressent à une seule IP avec un seul port dès qu’ils ont besoin d’avoir recours à un backend. Les backends vont recevoir la requête du frontend aléatoirement.
Les Services sont de trois types principaux :
-
ClusterIP: expose le service sur une IP interne au cluster appelée ClusterIP. Les autres pods peuvent alors accéder au service mais pas l’extérieur. -
NodePort: expose le service depuis l’IP publique de chacun des noeuds du cluster en ouvrant port directement sur le nœud, entre 30000 et 32767. Cela permet d’accéder aux pods internes répliqués. Comme l’IP est stable on peut faire pointer un DNS ou Loadbalancer classique dessus.
LoadBalancer: expose le service en externe à l’aide d’un Loadbalancer de fournisseur de cloud. Les services NodePort et ClusterIP, vers lesquels le Loadbalancer est dirigé sont automatiquement créés.