Cours 1 - Présentation de Kubernetes
Kubernetes est la solution dominante d’orchestration de conteneurs développée en Open Source au sein de la Cloud Native Computing Foundation.
Historique et popularité
![]()
Kubernetes est un orchestrateur développé originellement par Google et basé sur une dizaine d’années d’expérience de déploiement d’application énormes.
La première version est sortie en 2014 et K8S est devenu depuis l’un des projets open source les plus populaires du monde.
Autour de ce projet s’est développée la Cloud Native Computing Foundation qui comprend : Google, CoreOS, Mesosphere, Red Hat, Twitter, Huawei, Intel, Cisco, IBM, Docker, Univa et VMware.
Il s’agit d’une solution robuste, structurante et open source qui se construit autour des objectifs de:
- Rapidité
- Scaling des logiciels et des équipes de développement
- Abstraction et uniformisation des infrastructures
Architecture de Kubernetes
Les ressources k8s en (très) bref
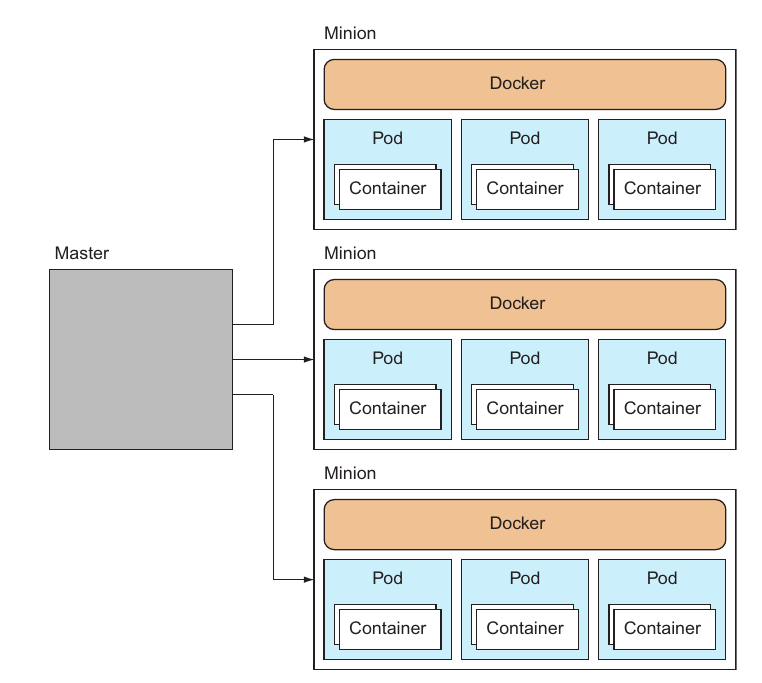
- Kubernetes a une architecture master/worker (cf. cours 2) composés d’un control plane et de nœuds workers.
- Les pods Kubernetes servent à grouper des conteneurs fortement couplés en unités d’application
- Les deployments sont une abstraction pour créer ou mettre à jour (ex : scaler) des groupes de pods.
- Enfin, les services sont des groupes de pods (des deployments) exposés à l’intérieur ou à l’extérieur du cluster.
Points forts de Kubernetes
- Open source et très actif.
- Une communauté très visible et présente dans l’évolution de l’informatique.
- Un standard collectif qui permet une certaine interopérabilité dans le cloud.
- Les pods tendent à se rapprocher plus d’une VM du point de vue de l’application (ressources de calcul garanties, une ip joignable sur le réseau local, multiprocess).
- Hébergeable de façon quasi-identique dans le cloud, on-premise ou en mixte.
- Kubernetes a un flat network ce qui permet de faire des choses puissante facilement comme le multi-datacenter.
- K8s est pensé pour la scalabilité et le calcul distribué.
Faiblesses de Kubernetes
-
Une difficulté à manier tout ce qui est stateful, comme des bases de données
- …même si les Operators et les CRD (Custom Resources Definitions) permettent de combler cette lacune dans la logique stateless de k8s
-
Beaucoup de points sont laissés à la décision du fournisseur de cloud ou des admins système :
-
Pas de solution de stockage par défaut, et parfois difficile de stocker “simplement” sans passer par les fournisseurs de cloud, ou par une solution de stockage décentralisé à part entière (Ceph, Gluster, Longhorn…)
- …même si ces solutions sont souvent bien intégrées à k8s
-
Beaucoup de solutions de réseau qui se concurrencent, demandant un comparatif fastidieux
- …même si plusieurs leaders émergent comme Calico, Flannel, Weave ou Cilium
-
Pas de solution de loadbalancing par défaut : soit on se base sur le fournisseur de cloud, soit on configure MetalLB
-
L’écosystème Kubernetes
Kubernetes n’est qu’un ensemble de standards. Il existe beaucoup de variétés (flavours) de Kubernetes, implémentant concrètement les solutions techniques derrière tout ce que Kubernetes ne fait que définir : solutions réseau, stockage (distribué ou non), loadbalancing, service de reverse proxy (Ingress), autoscaling de cluster (ajout de nouvelles VM au cluster automatiquement), monitoring…
Il est très possible de monter un cluster Kubernetes en dehors de ces fournisseurs, mais cela demande de faire des choix (ou bien une solution opinionated ouverte comme Rancher) et une relative maîtrise d’un nombre varié de sujets (bases de données, solutions de loadbalancing, redondance du stockage…).
C’est là la relative hypocrisie de Kubernetes : tout est ouvert et standardisé, mais devant la (relative) complexité et connaissance nécessaire pour mettre en place sa propre solution (de stockage distribué par exemple), nous retombons rapidement dans la facilité et les griffes du vendor lock-in (enfermement propriétaire).
Google Kubernetes Engine (GKE) (Google Cloud Plateform)
L’écosystème Kubernetes développé par Google. Très populaire car très flexible tout en étant l’implémentation de référence de Kubernetes.
Azure Kubernetes Services (AKS) (Microsoft Azure)
Un écosystème Kubernetes axé sur l’intégration avec les services du cloud Azure (stockage, registry, réseau, monitoring, services de calcul, loadbalancing, bases de données…).
Elastic Kubernetes Services (EKS) (Amazon Web Services)
Un écosystème Kubernetes assez standard à la sauce Amazon axé sur l’intégration avec le cloud Amazon (la gestion de l’accès, des loadbalancers ou du scaling notamment, le stockage avec Amazon EBS, etc.)
Rancher
Un écosystème Kubernetes très complet, assez opinionated et entièrement open-source, non lié à un fournisseur de cloud. Inclut l’installation de stack de monitoring (Prometheus), de logging, de réseau mesh (Istio) via une interface web agréable. Rancher maintient aussi de nombreuses solutions open source, comme par exemple Longhorn pour le stockage distribué.
k3s
Un écosystème Kubernetes fait par l’entreprise Rancher et axé sur la légèreté. Il remplace etcd par une base de données Postgres, utilise Traefik pour l’ingress et Klipper pour le loadbalancing.
Openshift
Une version de Kubernetes configurée et optimisée par Red Hat pour être utilisée dans son écosystème. Tout est intégré donc plus guidé, avec l’inconvénient d’être un peu captif·ve de l’écosystème et des services vendus par Red Hat.
Concurrents
Apache Mesos
Mesos est une solution plus générale que Kubernetes pour exécuter des applications distribuées. En combinant Mesos avec son “application framework” Marathon on obtient une solution équivalente sur de nombreux points à Kubernetes.
Elle est cependant moins standard : - Moins de ressources disponibles pour apprendre, intégrer avec d’autre solution etc. - Peu vendu en tant que service par les principaux cloud provider. - Plus chère à mettre en oeuvre.
Comparaison d’architecture : Mesos vs. Kubernetes
Parenthèse : Le YAML
Kubernetes décrit ses ressources en YAML. A quoi ça ressemble, YAML ?
- marché:
lieu: Marché de la Place
jour: jeudi
horaire:
unité: "heure"
min: 12
max: 20
fruits:
- nom: pomme
couleur: "verte"
pesticide: avec
- nom: poires
couleur: jaune
pesticide: sans
légumes:
- courgettes
- salade
- potiron
Syntaxe
-
Alignement ! (2 espaces !!)
-
ALIGNEMENT !! (comme en python)
-
ALIGNEMENT !!! (le défaut du YAML, pas de correcteur syntaxique automatique, c’est bête mais vous y perdrez forcément du temps !)
-
des listes (tirets)
-
des paires clé: valeur
-
Un peu comme du JSON, avec cette grosse différence que le JSON se fiche de l’alignement et met des accolades et des points-virgules
-
les extensions Kubernetes et YAML dans VSCode vous aident à repérer des erreurs