Cours 3 - Organiser un projet
Organisation d’un dépôt de code Ansible
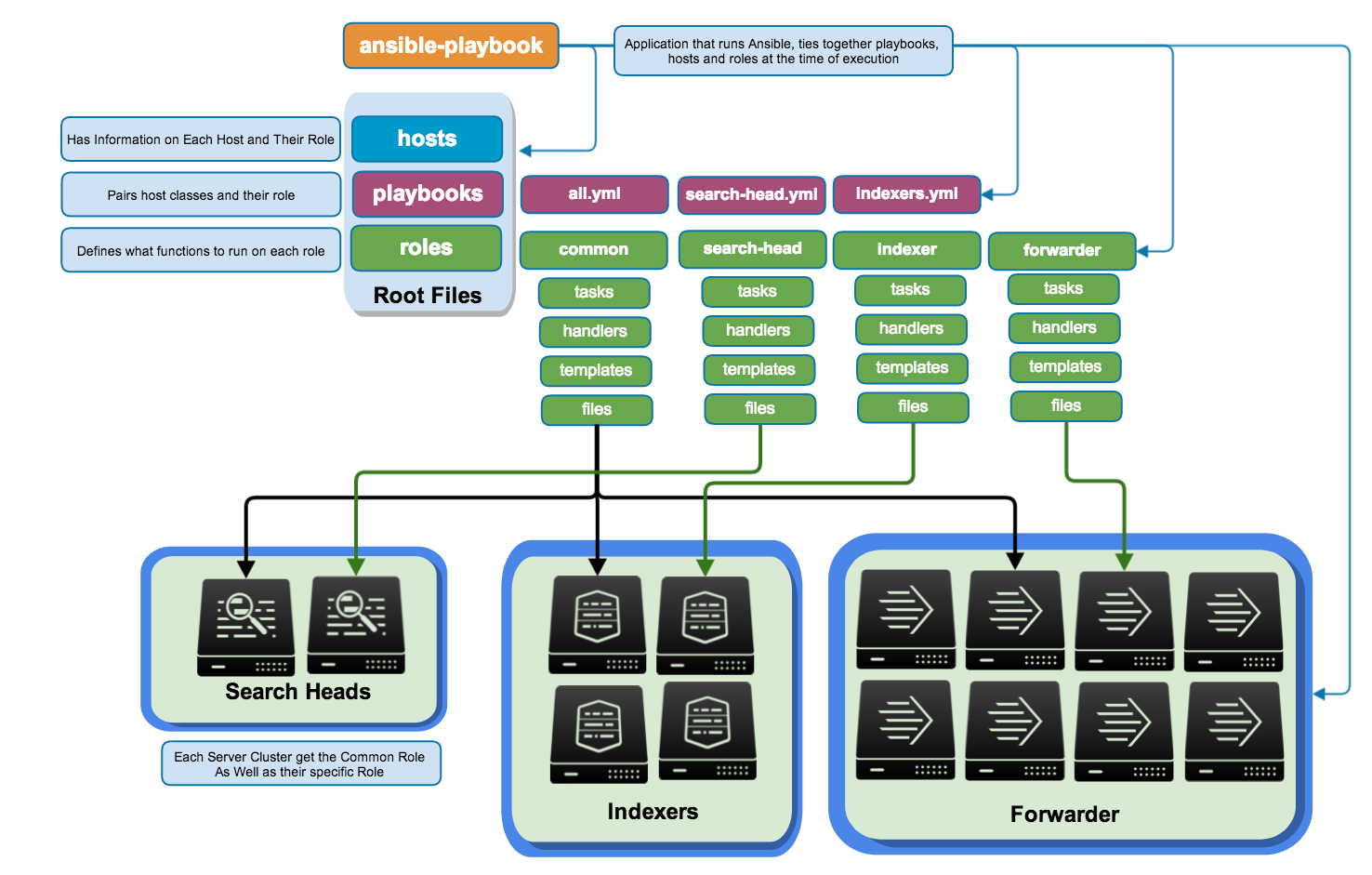
Voici, extrait de la documentation Ansible sur les “Best Practice”, l’une des organisations de référence d’un projet ansible de configuration d’une infrastructure:
production # inventory file for production servers
staging # inventory file for staging environment
group_vars/
group1.yml # here we assign variables to particular groups
group2.yml
host_vars/
hostname1.yml # here we assign variables to particular systems
hostname2.yml
site.yml # master playbook
webservers.yml # playbook for webserver tier
dbservers.yml # playbook for dbserver tier
roles/
common/ # this hierarchy represents a "role"
... # role code
webtier/ # same kind of structure as "common" was above, done for the webtier role
monitoring/ # ""
fooapp/ # ""
Plusieurs remarques:
- Chaque environnement (staging, production) dispose d’un inventaire, ce qui permet de préciser au runtime quel environnement cibler avec l’option
--inventory production. - Chaque groupe de serveurs (tier) dispose de son playbook
- qui s’applique sur le groupe en question.
- éventuellement définit quelques variables spécifiques (mais il vaut mieux les mettre dans l’inventaire ou les dossiers cf suite).
- Idéalement contient un minimum de tâches et plutôt des rôles
- Pour limiter la taille de l’inventaire principal on range les variables communes dans des dossiers
group_varsethost_vars. On met à l’intérieur un fichier<nom_du_groupe>.ymlqui contient un dictionnaire de variables. - On cherche à modulariser au maximum la configuration dans des rôles, c’est-à-dire des groupes de tâches rendues génériques et specifiques à un objectif de configuration.
- Ce modèle d’organisation correspond plutôt à la configuration de base d’une infrastructure (playbooks à exécuter régulièrement) qu’à l’usage de playbooks ponctuels comme pour le déploiement. Mais, bien sûr, on peut ajouter un dossier
playbooksouoperationspour certaines opérations ponctuelles. (cf cours 4) - Si les modules de Ansible (complétés par les commandes bash) ne suffisent pas on peut développer ses propres modules Ansible.
- Il s’agit de programmes Python plus ou moins complexes
- On les range alors dans le dossier
librarydu projet ou d’un rôle et on le précise éventuellement dansansible.cfg.
- Observons le rôle
common: il est utilisé ici pour rassembler les tâches de base et communes à toutes les machines. Par exemple s’assurer que les clés ssh de l’équipe sont présentes, que les dépôts spécifiques sont présents, etc.
Rôles Ansible
Objectif:
-
Découper les tâches de configuration en sous-ensembles réutilisables (une suite d’étapes de configuration).
-
Ansible est une sorte de langage de programmation et l’intérêt du code est de pouvoir créer des fonctions regroupées en librairies et les composer. Les rôles sont les “librairies” Ansible en quelque sorte.
-
Comme une fonction, un rôle prend généralement des paramètres qui permettent de personnaliser son comportement.
-
Tout le nécessaire doit y être (fichiers de configurations, archives et binaires à déployer, modules personnels dans
libraryetc.) -
Remarque : ne pas confondre modules et roles.
fileest un module,geerlingguy.dockerest un rôle. On doit écrire des rôles pour coder correctement en Ansible, on peut écrire des modules mais c’est largement facultatif car la plupart des actions existent déjà. -
Présentation d’un exemple de rôle : https://github.com/geerlingguy/ansible-role-docker
- Dans la philosophie Ansible on recherche la généricité des rôles. On cherche à ajouter des paramètres pour que le rôle s’adapte à différents cas (comme notre playbook flask app).
- Une bonne pratique: préfixer le nom des paramètres par le nom du rôle. Exemple :
docker_edition. - La généricité est nécessaire quand on veut distribuer le rôle ou construire des outils spécifiques qui servent à plusieurs endroit de l’infrastructure
- mais elle augmente la complexité
- donc pour les rôles internes on privilégie la simplicité, et le rôle fait sur mesure, plutôt que générique à de nombreux contexte
- Les rôles contiennent idéalement un fichier
READMEpour en décrire l’usage et un fichiermeta/main.ymlqui décrit la compatibilité et les dépendances, en plus de la licence et l’auteur. - Il doivent idéalement être versionnés dans des dépôts à part et installés avec la commande
ansible-galaxy.
Structure d’un rôle
Un rôle est un dossier avec des sous-dossiers conventionnels:
roles/
my_role/ # hiérarchie du rôle "my_role"
tasks/ #
main.yml # <-- le fichier de tâches exécuté par défaut
handlers/ #
main.yml # <-- les handlers
templates/ # <-- dossier des templates
ntp.conf.j2 # <------- les templates finissent par .j2
files/ #
foo.sh # <-- d'autres fichiers si nécessaire
vars/ #
main.yml # <-- variables internes du rôle
defaults/ #
main.yml # <-- variables par défaut pour le rôle
meta/ #
main.yml # <-- informations sur le rôle
On constate que les noms des sous-dossiers correspondent souvent à des sections du playbook. En fait le principe de base est d’extraire les différentes listes de tâches ou de variables dans des sous-dossiers.
-
Remarque : les fichiers de liste doivent nécessairement s’appeler main.yml" (pas très intuitif)
-
Remarque 2 :
main.ymlpeut en revanche importer d’autres fichiers aux noms personnalisés (ex: rôle docker de geerlingguy) -
Le dossier
defaultscontient les valeurs par défaut des paramètres du rôle. Ces valeurs ne sont jamais prioritaires (elles sont écrasées par n’importe quelle autre définition de la même variable ailleurs dans le code Ansible) -
Le fichier
meta/main.ymlest facultatif mais conseillé et contient des informations sur le rôle- auteur.ice
- licence
- compatibilité
- version
- dépendances à d’autres rôles.
-
Le dossier
filescontient les fichiers qui ne sont pas des templates (pour les modulecopyousync,scriptetc).
Ansible Galaxy
C’est le store de rôles officiel d’Ansible : https://galaxy.ansible.com/
C’est également le nom d’une commande ansible-galaxy qui permet d’installer des rôles et leurs dépendances depuis internet. Un sorte de gestionnaire de paquets pour Ansible.
Elle est utilisée généralement sour la forme ansible install -r roles/requirements.yml -p roles <nom_role>, ou plus simplement ansible-galaxy install <role> (mais installe dans /etc/ansible/roles dans ce cas).
Tous les rôles Ansible sont communautaires (pas de rôles officiels) et généralement stockés sur Github ou Gitlab.
Mais on peut voir la popularité (étoiles Github), et la présence de tests (avec un outil Ansible appelé Molecule), qui garantissement la plus ou moins grande fiabilité et qualité du rôle.
Il existe des rôles pour installer un peu n’importe quelle application serveur courante aujourd’hui. Passez du temps à explorer le web avant de développer quelque chose avec Ansible.
Installer des rôles avec requirements.yml
Conventionnellement on utilise un fichier requirements.yml situé dans roles pour décrire la liste des rôles nécessaires à un projet.
- src: geerlingguy.repo-epel
- src: geerlingguy.haproxy
- src: geerlingguy.docke
# from GitHub, overriding the name and specifying a specific tag
- src: https://github.com/bennojoy/nginx
version: master
name: nginx_role
- Ensuite pour les installer on lance:
ansible-galaxy install -r roles/requirements.yml -p roles.
Imports et includes
Il est possible d’importer le contenu d’autres fichiers dans un playbook:
import_tasks: importe une liste de tâches (atomiques)import_playbook: importe une liste de play contenus dans un playbook.
Les deux instructions précédentes désignent un import statique qui est résolu avant l’exécution.
Au contraire, include_tasks permet d’intégrer une liste de tâche dynamiquement pendant l’exécution.
Par exemple :
vars:
apps:
- app1
- app2
- app3
tasks:
- include_tasks: install_app.yml
loop: "{{ apps }}"
Ce code indique à Ansible d’exécuter une série de tâches pour chaque application de la liste. On pourrait remplacer cette liste par une liste dynamique. Comme le nombre d’imports ne peut pas facilement être connu à l’avance on doit utiliser include_tasks.
Savoir si on doit utiliser include ou import se fait selon les cas et avec tâtonnement le plus souvent.