Introduction
DevOps
Le nouveau paradigme de l’informatique
Supports de formation : Elie Gavoty et Hadrien Pélissier Conçus initialement dans le cadre d'un cursus Uptime Formation. Sous licence CC-BY-NC-SA - Docker - Avril 2021
Le nouveau paradigme de l’informatique
Hadrien Pélissier
“Le DevOps est un mouvement qui s’attaque au conflit existant structurellement entre le développement de logiciels et les opérations. Ce conflit résulte d’objectifs et de motivations divergents. Le DevOps améliore la collaboration entre les départements du développement et des opérations et rationalise l’ensemble de l’organisation. (Citation de Hütterman 2012 - Devops for developers)”
Traditionnellement la qualité logicielle provient :
Problèmes historiques posé par trop de spécification et validation humaine :
process formels : ennuyeux et abstraitMais l’agilité traditionnelle ne concerne pas l’administration système.
Exemple : Netflix ou Spotify ou Facebook etc. déploient une nouvelle version mineure de leur logiciel par jour.
La célérité et l’agrandissementest sont incompatibles avec une administration système traditionnelle:
Dans un DSI (département de service informatique) on organise ces activités d’admin sys en opérations:
La difficulté principale pour les Ops c’est qu’un système informatique est:
On peut donc constater que les opérations traditionnelles implique une culture de la prudence
Les opérations “traditionnelles”:
Du côté des développeur·euses avec l’agilité on a déjà depuis des années une façon d’automatiser pleins d’opérations sur le code à chaque fois qu’on valide une modification.
C’est ce qu’on appelle l’intégration continue.
Le principe central du DevOps est d’automatiser également les opérations de déploiement et de maintenance en se basant sur le même modèle.
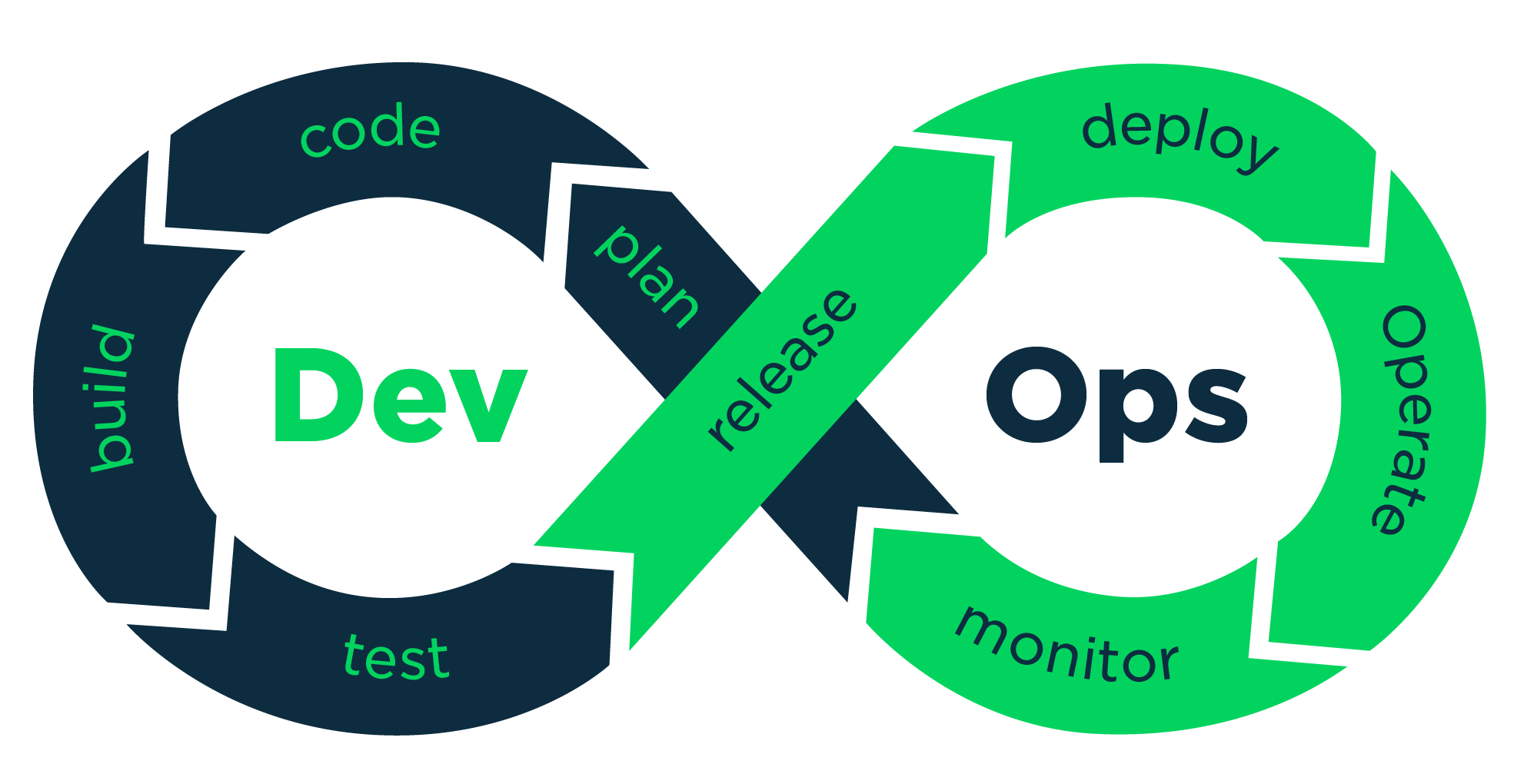
Mais pour que ça fonctionne il faut résoudre des défi techniques nouveau => innovations
Dans le cadre d’un produit logiciel, les administrateurs systèmes sont rassemblées avec le développement et le chef produit : tout le monde fait les réunions ensemble pour se parler et se comprendre.
Les développeur·euses peuvent plus facilement créer un environnement réaliste pour jouer avec et comprendre comment fonctionne l’infrastructure de production (ils progressent dans l’administration système et la compréhension des enjeux opérationnels).
Les adminsys apprennent à programmer leurs opérations de façon puissante il deviennent donc plus proche de la logique des développeur·euses. (grace à l’Infrastructure as Code)
Par abus de langage on dit un ou une DevOps pour parler d’un métier spécifique dans une entreprise. Je dis que je suis DevOps sur mon CV par exemple.
Vous pouvez retenir :
Il faut être polyvalent : bien connaître l’administration système Linux mais aussi un peu la programmation et le développement.
Il faut connaître les nouvelles bonnes pratiques et les nouveaux outils cités précédemment.
“Machines ain’t smart. You are!” Comment dire correctement aux machines quoi faire ?
Plutôt que d'installer manuellement de nouveaux serveurs linux pour faire tourner des logiciels on peut utiliser des outils pour faire apparaître de nouveaux serveurs à la demande.
Du coup on peut agrandir sans effort l’infrastructure de production pour délivrer une nouvelle version
C’est ce qu’on appelle le IaaS (Infrastructure as a service)
Accélérer la livraison des nouvelles versions du logiciel.
Des tests systématiques et automatisés pour ne pas se reposer sur la vérification humaine.
Un déploiement progressif en parallèle (Blue/Green) pour pouvoir automatiser le Rollback et être serein.
A chaque étape le code passe dans un Pipeline de validation automatique.
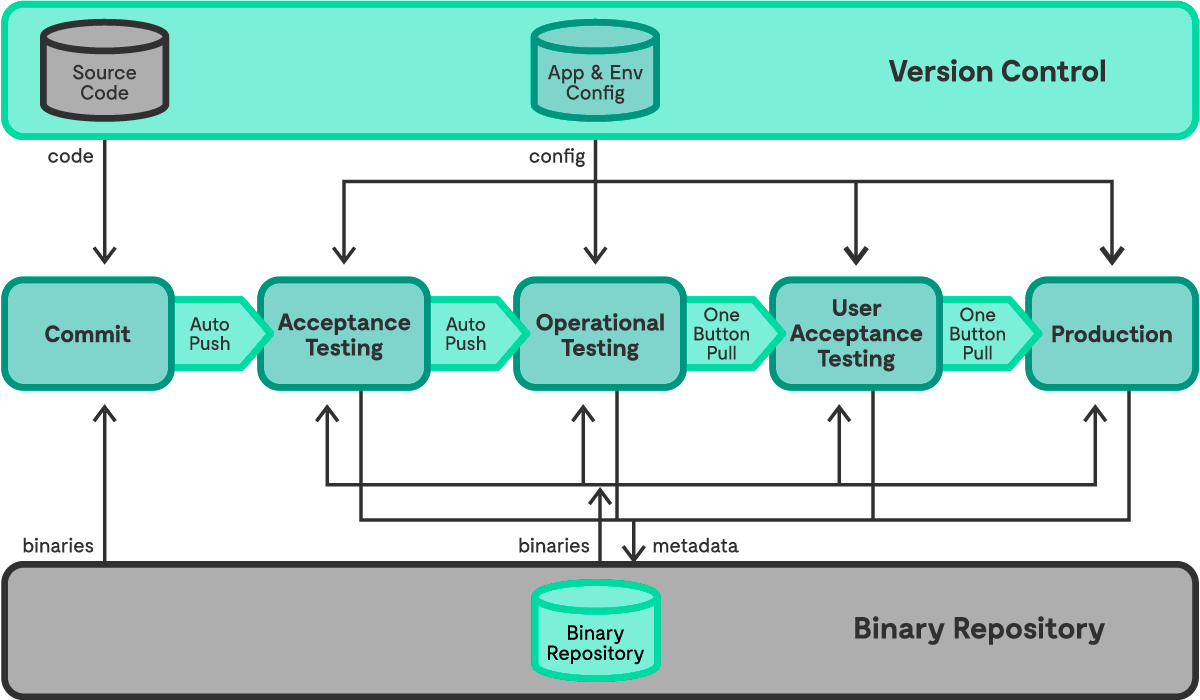
Permet de régler un problème de l’administration système : Difficultée l’état du système à un instant T ce qui augmente les risques.
Plutôt que d’appliquer des commandes puis d’oublier si on les a appliqué, On décrit le système d’exploitation (l’état du linux) dans un fichier et on utilise un système qui applique cette configuration explicite à tout moment.
Permet aux Ops/AdminSys de travailler comme des développeur·euses (avec une usine logicielle et ses outils)
Un mouvement d’informatique lié au DevOps et au cloud :
Une façon de définir une infrastructure dans un fichier descriptif et ainsi de créer dynamiquement des services.
Assez différent de l’administration système sur mesure (= méthode de résolution plus ou moins rigoureuse à chaque nouveau bug)
Infrastructure as a Service (commercial et logiciel)
Plateform as a Service - Heroku, cluster Kubernetes Avec une offre d’hébergement de conteneurs, on parle la plupart du temps de Platform as a Service.
Il s’agit comme son nom l’indique de gérer les infrastructures en tant que code c’est-à-dire des fichiers textes avec une logique algorithmique/de données et suivis grâce à un gestionnaire de version (git).
Le problème identifié que cherche a résoudre l’IaC est un écheveau de difficulées pratiques rencontrée dans l’administration système traditionnelle:
Faire des boîtes isolées avec nos logiciels:
Docker (et un peu LXC)
Il s’agit de mettre en quelques sortes les logiciels dans des boîtes :
Avec tout ce qu’il faut pour qu’ils fonctionnent (leurs dépendances).
Ces boîtes sont fermées (on peut ne peux plus les modifier). On parle d'immutabilité.
Si on a besoin d’un nouvelle version on fait un nouveau modèle de boîte. (on dit une nouvelle image docker)
Cette nouvelle image permet de créer autant d’instances que nécessaire.
L’isolation des containers permet d’éviter que les logiciels s’emmêlent entre eux. (Les dépendances ne rentrent pas en conflit)
Les conteneurs non modifiables permettent de savoir exactement l’état de ce qu’on exécute sur l’ordinateur
Le risque de bug diminue énormément : fiabilisation
Les supports de présentation et les TD sont disponibles à l’adresse https://cours.hadrienpelissier.fr
Pour exporter les TD utilisez la fonction d’impression pdf de google chrome.
⚠️ Pour l’anglais, si un texte ne vous paraît pas clair, quelques liens :
Les TP sont réalisables dans une VM disponible depuis votre navigateur, en allant sur https://lab.hadrienpelissier.fr
Se connecter avec votreprenom (en minuscules) et le mot de passe donné.
Puis cliquez sur la machine vnc-votreprenom (si besoin, le mot de passe dans la VM est le même que celui pour accéder au lab)
Ouvrez un autre onglet et cliquez aussi sur la machine appelée vnc-formateur-...
Pour faire un copier-coller depuis l’extérieur à votre VM, il faut appuyer sur les touches Ctrl+Alt+Maj, puis coller ce que l’on veut dans le presse-papier, et refermer la sidebar avec Ctrl+Alt+Maj.
snap install code --classicapt) installez git, htop, ncduDécouvrir le couteau suisse de l’automatisation et de l’infrastructure as code.
ansible et ses optionsAnsible est un gestionnaire de configuration et un outil de déploiement et d’orchestration très populaire et central dans le monde de l'infrastructure as code (IaC).
Il fait donc également partie de façon centrale du mouvement DevOps car il s’apparente à un véritable couteau suisse de l’automatisation des infrastructures.
Ansible a été créé en 2012 (plus récent que ses concurrents Puppet et Chef) autour d’une recherche de simplicité et du principe de configuration agentless.
Très orienté linux/opensource et versatile il obtient rapidement un franc succès et s’avère être un couteau suisse très adapté à l’automatisation DevOps et Cloud dans des environnements hétérogènes.
Red Hat rachète Ansible en 2015 et développe un certain nombre de produits autour (Ansible Tower, Ansible container avec Openshift).
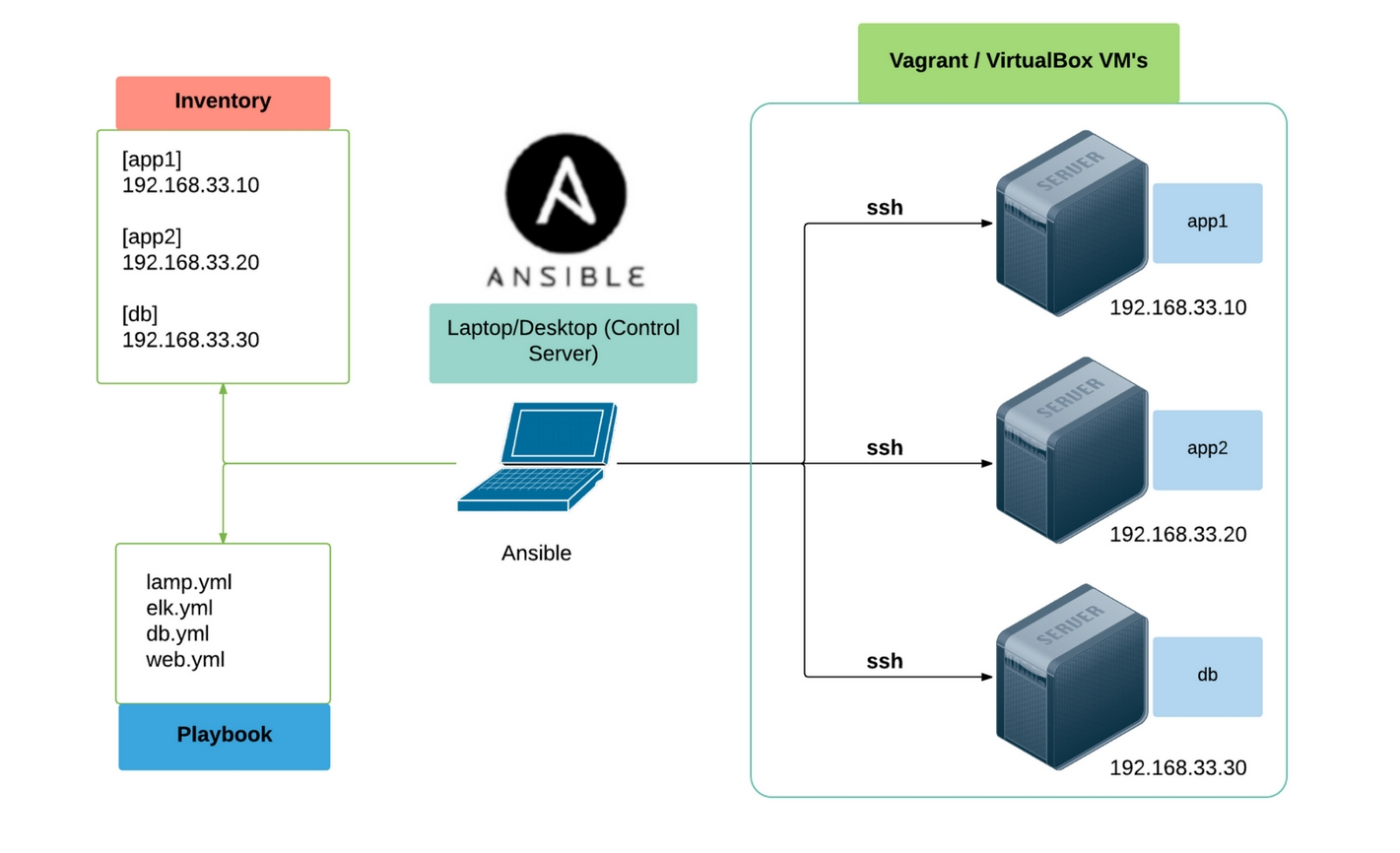
Ansible est agentless c’est à dire qu’il ne nécessite aucun service/daemon spécifique sur les machines à configurer.
La simplicité d’Ansible provient également du fait qu’il s’appuie sur des technologies linux omniprésentes et devenues universelles.
De fait Ansible fonctionne efficacement sur toutes les distributions linux, debian, centos, ubuntu en particulier (et maintenant également sur Windows).
Ansible est semi-déclaratif c’est à dire qu’il s’exécute séquentiellement mais idéalement de façon idempotente.
Il permet d’avoir un état descriptif de la configuration:
Peut être utilisé pour des opérations ponctuelles comme le déploiement:
Les cas d’usages d’Ansible vont de …:
petit:
moyen:
grand:
Ansible est très complémentaire à docker:
docker_container.Plus récemment avec l’arrivé d'Ansible container il est possible de construire et déployer des conteneurs docker avec du code ansible. Cette solution fait partie de la stack Red Hat Openshift. Concrêtement le langage ansible remplace (avantageusement ?) le langage Dockerfile pour la construction des images Docker.
Pour l’installation plusieurs options sont possibles:
sudo apt-add-repository --yes --update ppa:ansible/ansiblepip le gestionnaire de paquet du langage python: sudo pip3 install
sudo pip3 install ansible --upgradePour voir l’ensemble des fichier installé par un paquet pip3 :
pip3 show -f ansible | less
Pour tester la connexion aux serveurs on utilise la commande ad hoc suivante. ansible all -m ping
Il s’agit d’une liste de machines sur lesquelles vont s’exécuter les modules Ansible. Les machines de cette liste sont:
Exemple :
[all:vars]
ansible_ssh_user=elie
ansible_python_interpreter=/usr/bin/python3
[awx_nodes]
awxnode1 node_state=started ansible_host=10.164.210.101 container_image=centos_ansible_20190901
[dbservers]
pgnode1 node_state=started ansible_host=10.164.210.111 container_image=centos_ansible_20190901
pgnode2 node_state=started ansible_host=10.164.210.112 container_image=centos_ansible_20190901
[appservers]
appnode1 node_state=started ansible_host=10.164.210.121 container_image=centos_ansible_20190901
appnode2 node_state=started ansible_host=10.164.210.122 container_image=centos_ansible_20190901
Les inventaires peuvent également être au format YAML (plus lisible mais pas toujours intuitif) ou JSON (pour les machines).
Ansible se configure classiquement au niveau global dans le dossier /etc/ansible/ dans lequel on retrouve en autre l’inventaire par défaut et des paramètre de configuration.
Ansible est très fortement configurable pour s’adapter à des environnement contraints. Liste des paramètre de configuration:
Alternativement on peut configurer ansible par projet avec un fichier ansible.cfg présent à la racine. Toute commande ansible lancée à la racine du projet récupère automatiquement cette configuration.
ansibleversion minimale :
ansible <groupe_machine> -m <module> -a <arguments_module>
ansible all -m ping: Permet de tester si les hotes sont joignables et ansible utilisable (SSH et python sont présents et configurés).
version plus complète :
ansible <groupe_machine> --inventory <fichier_inventaire> --become -m <module> -a <arguments_module>
Ansible fonctionne grâce à des modules python téléversés sur sur l’hôte à configurer puis exécutés. Ces modules sont conçus pour être cohérents et versatiles et rendre les tâches courantes d’administration plus simples.
Il en existe pour un peu toute les tâches raisonnablement courantes : un slogan Ansible “Batteries included” ! Plus de 1300 modules sont intégrés par défaut.
ping: un module de test Ansible (pas seulement réseau comme la commande ping)
yum/apt: pour gérer les paquets sur les distributions basées respectivement sur Red Hat ou Debian.
... -m yum -a "name=openssh-server state=present"
systemd (ou plus générique service): gérer les services/daemons d’un système.... -m systemd -a "name=openssh-server state=started"
user: créer des utilisateurs et gérer leurs options/permission/groupes
file: pour créer, supprimer, modifier, changer les permission de fichiers, dossier et liens.
shell: pour exécuter des commandes unix grace à un shell
La documentation des modules Ansible se trouve à l’adresse https://docs.ansible.com/ansible/latest/modules/file_module.html
Chaque module propose de nombreux arguments pour personnaliser son comportement:
exemple: le module file permet de gérer de nombreuses opérations avec un seul module en variant les arguments.
Il est également à noter que la plupart des arguments sont facultatifs.
Exemple et bonne pratique: toujours préciser state: present même si cette valeur est presque toujours le défaut implicite.
Pour rappel, les avantages du code Ansible, qui donne tout son intérêt à l’Infrastructure-as-Code sont :
La dimension incrémentale du code rend en particulier plus aisé de construire une infrastructure progressivement en la complexifiant au fur et à mesure plutôt que de devoir tout plannifier à l’avance.
Le playbook est une sorte de script Ansible, c’est-à-dire du code.
Le nom provient du football américain : il s’agit d’un ensemble de stratégies qu’une équipe a travaillé pour répondre aux situations du match. Elle insiste sur la versatilité de l’outil.
Les playbooks ansible sont écrits au format YAML.
A quoi ça ressemble ?
- 1
- Poire
- "Message à caractère informatif"
clé1: valeur1
clé2: valeur2
clé3: 3
marché: # début du dictionnaire global "marché"
lieu: Crimée Curial
jour: dimanche
horaire:
unité: "heure"
min: 9
max: 14 # entier
fruits: # liste de dictionnaires décrivant chaque fruit
- nom: pomme
couleur: "verte"
pesticide: avec # les chaines sont avec ou sans " ou '
- nom: poires
couleur: jaune
pesticide: sans
légumes: # liste de 3 éléments
- courgettes
- salade
# on peut sauter des lignes sans interrompre la liste ou le dictionnaire en cours
- potiron
# fin du dictionnaire global
Pour mieux visualiser l’imbrication des dictionnaires et des listes en YAML on peut utiliser un convertisseur YAML -> JSON : https://www.json2yaml.com/.
Notre marché devient:
{
"marché": {
"lieu": "Crimée Curial",
"jour": "dimanche",
"horaire": {
"unité": "heure",
"min": 9,
"max": 14
},
"fruits": [
{
"nom": "pomme",
"couleur": "verte",
"pesticide": "avec"
},
{
"nom": "poires",
"couleur": "jaune",
"pesticide": "sans"
}
],
"légumes": [
"courgettes",
"salade",
"potiron"
]
}
}
Observez en particulier la syntaxe assez condensée de la liste “fruits” en YAML qui est une liste de dictionnaires.
---
- name: premier play # une liste de play (chaque play commence par un tiret)
hosts: serveur_web # un premier play
become: yes
gather_facts: false # récupérer le dictionnaires d'informations (facts) relatives aux machines
vars:
logfile_name: "auth.log"
var_files:
- mesvariables.yml
pre_tasks:
- name: dynamic variable
set_fact:
mavariable: "{{ inventory_hostname + 'prod' }}" #guillemets obligatoires
rôles:
- flaskapp
tasks:
- name: installer le serveur nginx
apt: name=nginx state=present # syntaxe concise proche des commandes ad hoc mais moins lisible
- name: créer un fichier de log
file: # syntaxe yaml extensive : conseillée
path: /var/log/{{ logfile_name }} #guillemets facultatifs
mode: 755
- import_tasks: mestaches.yml
handlers:
- systemd:
name: nginx
state: "reloaded"
- name: un autre play
hosts: dbservers
tasks:
...
Un playbook commence par un tiret car il s’agit d’une liste de plays.
Un play est un dictionnaire yaml qui décrit un ensemble de tâches ordonnées en plusieurs sections. Un play commence par préciser sur quelles machines il s’applique puis précise quelques paramètres faculatifs d’exécution comme become: yes pour l’élévation de privilège (section hosts).
La section hosts est obligatoire. Toutes les autres sections sont facultatives !
La section tasks est généralement la section principale car elle décrit les tâches de configuration à appliquer.
La section tasks peut être remplacée ou complétée par une section roles et des sections pre_tasks post_tasks
Les handlers sont des tâches conditionnelles qui s’exécutent à la fin (post traitements conditionnels comme le redémarrage d’un service)
pre_tasksrolestaskspost_taskshandlersLes rôles ne sont pas des tâches à proprement parler mais un ensemble de tâches et ressources regroupées dans un module, un peu comme une librairie dans le développement. Nous explorerons les rôles au cours 3.
name: qui décrit lors de l’exécution la tâche en cours : un des principes de l’Infrastructure-as-Code est l’intelligibilité des opérations.Pour valider la syntaxe il est possible d’installer et utiliser ansible-linter sur les fichiers YAML.
L’élévation de privilège est nécessaire lorsqu’on a besoin d’être root pour exécuter une commande ou plus généralement qu’on a besoin d’exécuter une commande avec un utilisateur différent de celui utilisé pour la connexion on peut utiliser:
Au moment de l’exécution l’argument --become en ligne de commande avec ansible, ansible-console ou ansible-playbook.
La section become: yes
hosts) : toutes les tâches seront executée avec cette élévation par défaut.Pour executer une tâche avec un autre utilisateur que root (become simple) ou celui de connexion (sans become) on le précise en ajoutant à become: yes, become_user: username
Ansible utilise en arrière plan un dictionnaire contenant de nombreuses variables.
Pour s’en rendre compte on peut lancer :
ansible <hote_ou_groupe> -m debug -a "msg={{ hostvars }}"
Ce dictionnaire contient en particulier:
ansible_user par exemple)ansible_os_family) et récupéré au lancement d’un playbook.La plupart des fichiers Ansible (sauf l’inventaire) sont traités avec le moteur de template python JinJa2.
Ce moteur permet de créer des valeurs dynamiques dans le code des playbooks, des rôles, et des fichiers de configuration.
Les variables écrites au format {{ mavariable }} sont remplacées par leur valeur provenant du dictionnaire d’exécution d’Ansible.
Des filtres (fonctions de transformation) permettent de transformer la valeur des variables: exemple : {{ hostname | default('localhost') }} (Voir plus bas)
Les fichiers de templates (.j2) utilisés avec le module template, généralement pour créer des fichiers de configuration peuvent contenir des variables et des filtres comme les fichier de code (voir au dessus) mais également d’autres constructions jinja2 comme:
if : {% if nginx_state == 'present' %}...{% endif %}.for : {% for host in groups['appserver'] %}...{% endfor %}.{% include 'autre_fichier_template.j2' %}On peut définir et modifier la valeur des variables à différents endroits du code ansible:
vars: du playbook.var_files:group_vars, host_barsdefaults des rôles (cf partie sur les rôles)set_facts.--extra-vars "version=1.23.45 other_variable=foo"Lorsque définies plusieurs fois, les variables ont des priorités en fonction de l’endroit de définition.
L’ordre de priorité est plutôt complexe: https://docs.ansible.com/ansible/latest/user_guide/playbooks_variables.html#variable-precedence-where-should-i-put-a-variable
En résumé la règle peut être exprimée comme suit: les variables de runtime sont prioritaires sur les variables dans un playbook qui sont prioritaires sur les variables de l’inventaire qui sont prioritaires sur les variables par défaut d’un rôle.
groups.all et groups['all'] sont deux syntaxes équivalentes pour désigner les éléments d’un dictionnaire.https://docs.ansible.com/ansible/latest/reference_appendices/special_variables.html
Les plus utiles:
hostvars: dictionaire de toute les variables rangées par hote de l’inventaire.ansible_host: information utilisée pour la connexion (ip ou domaine).inventory_hostname: nom de la machine dans l’inventaire.groups: dictionnaire de tous les groupes avec la liste des machines appartenant à chaque groupe.Pour explorer chacune de ces variables vous pouvez utiliser le module debug en mode adhoc ou dans un playbook:
ansible <hote_ou_groupe> -m debug -a "msg={{ ansible_host }}"
ou encore:
ansible <hote_ou_groupe> -m debug -a "msg={{ groups.all }}"
Les facts sont des valeurs de variables récupérées au début de l’exécution durant l’étape gather_facts et qui décrivent l’état courant de chaque machine.
ansible_os_family est un fact/variable décrivant le type d’OS installé sur la machine. Elle n’existe qu’une fois les facts récupérés.! Lors d’une commande adhoc ansible les facts ne sont pas récupérés : la variable ansible_os_family ne sera pas disponible.
La liste des facts peut être trouvée dans la documentation et dépend des plugins utilisés pour les récupérés: https://docs.ansible.com/ansible/latest/user_guide/playbooks_vars_facts.html
whenElle permet de rendre une tâche conditionnelle (une sorte de if)
- name: start nginx service
systemd:
name: nginx
state: started
when: ansible_os_family == 'RedHat'
Sinon la tâche est sautée (skipped) durant l’exécution.
loop:Cette directive permet d’executer une tâche plusieurs fois basée sur une liste de valeur:
https://docs.ansible.com/ansible/latest/user_guide/playbooks_loops.html
exemple:
- hosts: localhost
tasks:
- name: exemple de boucle
debug:
msg: "{{ item }}"
loop:
- message1
- message2
- message3
On peut également controler cette boucle avec quelques paramètres:
- hosts: localhost
vars:
messages:
- message1
- message2
- message3
tasks:
- name: exemple de boucle
debug:
msg: "message numero {{ num }} : {{ message }}"
loop: "{{ messages }}"
loop_control:
loop_var: message
index_var: num
Cette fonctionnalité de boucle était anciennement accessible avec le mot clé with_items: qui est maintenant déprécié.
Pour transformer la valeur des variables à la volée lors de leur appel on peut utiliser des filtres (jinja2) :
{{ hostname | default('localhost') }}La liste complète des filtres ansible se trouve ici : https://docs.ansible.com/ansible/latest/user_guide/playbooks_filters.html
Avec Ansible on dispose d’au moins trois manières de debugger un playbook:
Rendre la sortie verbeuse (mode debug) avec -vvv.
Utiliser une tâche avec le module debug : debug msg="{{ mavariable }}".
Utiliser la directive debugger: always ou on_failed à ajouter à la fin d’une tâche. L’exécution s’arrête alors après l’exécution de cette tâche et propose un interpreteur de debug.
Les commandes et l’usage du debugger sont décrits dans la documentation: https://docs.ansible.com/ansible/latest/user_guide/playbooks_debugger.html
Voici, extrait de la documentation Ansible sur les “Best Practice”, l’une des organisations de référence d’un projet ansible de configuration d’une infrastructure:
production # inventory file for production servers
staging # inventory file for staging environment
group_vars/
group1.yml # here we assign variables to particular groups
group2.yml
host_vars/
hostname1.yml # here we assign variables to particular systems
hostname2.yml
site.yml # master playbook
webservers.yml # playbook for webserver tier
dbservers.yml # playbook for dbserver tier
roles/
common/ # this hierarchy represents a "role"
... # role code
webtier/ # same kind of structure as "common" was above, done for the webtier role
monitoring/ # ""
fooapp/ # ""
Plusieurs remarques:
--inventory production.group_vars et host_vars. On met à l’intérieur un fichier <nom_du_groupe>.yml qui contient un dictionnaire de variables.playbooks ou operations pour certaines opérations ponctuelles. (cf cours 4)library du projet ou d’un rôle et on le précise éventuellement dans ansible.cfg.common : il est utilisé ici pour rassembler les tâches de base et communes à toutes les machines. Par exemple s’assurer que les clés ssh de l’équipe sont présentes, que les dépôts spécifiques sont présents, etc.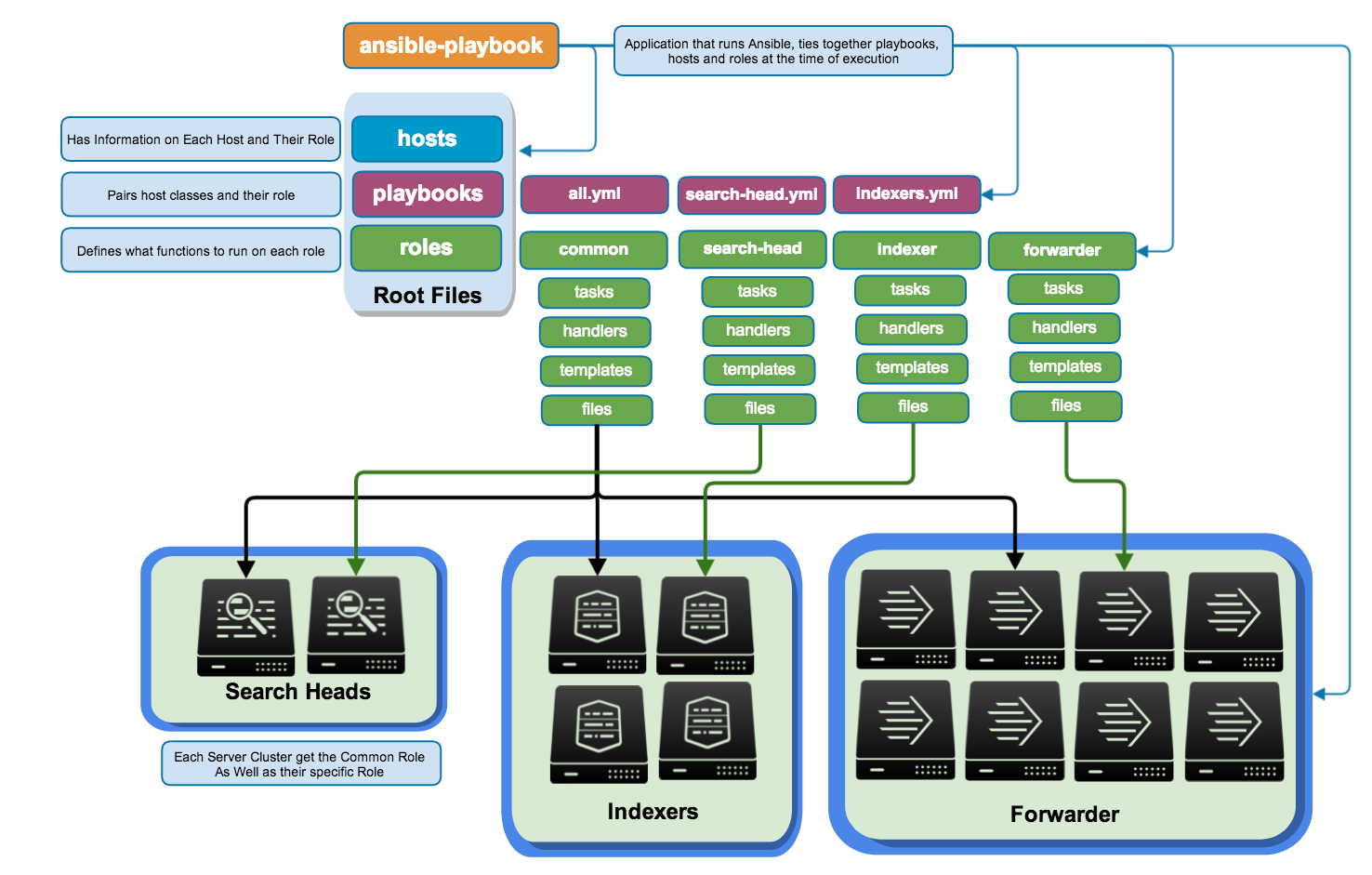
Découper les tâches de configuration en sous-ensembles réutilisables (une suite d’étapes de configuration).
Ansible est une sorte de langage de programmation et l’intérêt du code est de pouvoir créer des fonctions regroupées en librairies et les composer. Les rôles sont les “librairies” Ansible en quelque sorte.
Comme une fonction, un rôle prend généralement des paramètres qui permettent de personnaliser son comportement.
Tout le nécessaire doit y être (fichiers de configurations, archives et binaires à déployer, modules personnels dans library etc.)
Remarque : ne pas confondre modules et roles. file est un module, geerlingguy.docker est un rôle. On doit écrire des rôles pour coder correctement en Ansible, on peut écrire des modules mais c’est largement facultatif car la plupart des actions existent déjà.
Présentation d’un exemple de rôle : https://github.com/geerlingguy/ansible-role-docker
docker_edition.README pour en décrire l’usage et un fichier meta/main.yml qui décrit la compatibilité et les dépendances, en plus de la licence et l’auteur.ansible-galaxy.Un rôle est un dossier avec des sous-dossiers conventionnels:
roles/
my_role/ # hiérarchie du rôle "my_role"
tasks/ #
main.yml # <-- le fichier de tâches exécuté par défaut
handlers/ #
main.yml # <-- les handlers
templates/ # <-- dossier des templates
ntp.conf.j2 # <------- les templates finissent par .j2
files/ #
foo.sh # <-- d'autres fichiers si nécessaire
vars/ #
main.yml # <-- variables internes du rôle
defaults/ #
main.yml # <-- variables par défaut pour le rôle
meta/ #
main.yml # <-- informations sur le rôle
On constate que les noms des sous-dossiers correspondent souvent à des sections du playbook. En fait le principe de base est d’extraire les différentes listes de tâches ou de variables dans des sous-dossiers.
Remarque : les fichiers de liste doivent nécessairement s’appeler main.yml" (pas très intuitif)
Remarque 2 : main.yml peut en revanche importer d’autres fichiers aux noms personnalisés (ex: rôle docker de geerlingguy)
Le dossier defaults contient les valeurs par défaut des paramètres du rôle. Ces valeurs ne sont jamais prioritaires (elles sont écrasées par n’importe quelle autre définition de la même variable ailleurs dans le code Ansible)
Le fichier meta/main.yml est facultatif mais conseillé et contient des informations sur le rôle
Le dossier files contient les fichiers qui ne sont pas des templates (pour les module copy ou sync, script etc).
C’est le store de rôles officiel d’Ansible : https://galaxy.ansible.com/
C’est également le nom d’une commande ansible-galaxy qui permet d’installer des rôles et leurs dépendances depuis internet. Un sorte de gestionnaire de paquets pour Ansible.
Elle est utilisée généralement sour la forme ansible install -r roles/requirements.yml -p roles <nom_role>, ou plus simplement ansible-galaxy install <role> (mais installe dans /etc/ansible/roles dans ce cas).
Tous les rôles Ansible sont communautaires (pas de rôles officiels) et généralement stockés sur Github ou Gitlab.
Mais on peut voir la popularité (étoiles Github), et la présence de tests (avec un outil Ansible appelé Molecule), qui garantissement la plus ou moins grande fiabilité et qualité du rôle.
Il existe des rôles pour installer un peu n’importe quelle application serveur courante aujourd’hui. Passez du temps à explorer le web avant de développer quelque chose avec Ansible.
requirements.ymlConventionnellement on utilise un fichier requirements.yml situé dans roles pour décrire la liste des rôles nécessaires à un projet.
- src: geerlingguy.repo-epel
- src: geerlingguy.haproxy
- src: geerlingguy.docke
# from GitHub, overriding the name and specifying a specific tag
- src: https://github.com/bennojoy/nginx
version: master
name: nginx_role
ansible-galaxy install -r roles/requirements.yml -p roles.Il est possible d’importer le contenu d’autres fichiers dans un playbook:
import_tasks: importe une liste de tâches (atomiques)import_playbook: importe une liste de play contenus dans un playbook.Les deux instructions précédentes désignent un import statique qui est résolu avant l’exécution.
Au contraire, include_tasks permet d’intégrer une liste de tâche dynamiquement pendant l’exécution.
Par exemple :
vars:
apps:
- app1
- app2
- app3
tasks:
- include_tasks: install_app.yml
loop: "{{ apps }}"
Ce code indique à Ansible d’exécuter une série de tâches pour chaque application de la liste. On pourrait remplacer cette liste par une liste dynamique. Comme le nombre d’imports ne peut pas facilement être connu à l’avance on doit utiliser include_tasks.
Savoir si on doit utiliser include ou import se fait selon les cas et avec tâtonnement le plus souvent.
Les problématiques de sécurité Linux ne sont pas du tout résolues magiquement par Ansible. Tous le travail de réflexion et de sécurisation reste identique mais peut, comme le reste, être mieux controllé grâce à l’approche déclarative de l’infrastructure as code.
Si cette problématique des liens entre Ansible et sécurité vous intéresse, il existe un livre appelé Security automation with Ansible.
Il est à noter tout de même qu’Ansible est généralement apprécié d’un point de vue sécurité car il n’augmente pas (vraiment) la surface d’attaque de vos infrastructures : il est basé sur ssh qui est éprouvé et ne nécessite généralement pas de réorganisation des infrastructures.
Pour les cas plus spécifiques, Ansible est relativement agnostique du mode de connexion grâce aux plugins de connexions (voir ci-dessous).
Un bonne pratique : changer le port de connexion ssh pour un port atypique. Vous pourrez ajouter la variable ansible_ssh_port=17728 dans l’inventaire.
Il faut idéalement éviter de créer un seul compte Ansible de connexion pour toutes les machines :
Il faut utiliser comme nous avons fait dans les TP des logins ssh avec des utilisateurs aux noms correspondant aux usages ou aux humains derrière, et des clés ssh. C’est-à-dire le même modèle d’authentification que l’administration traditionnelle.
Le mode de connexion par défaut de Ansible est SSH, cependant il est possible d’utiliser de nombreux autres modes de connexion spécifiques :
Pour afficher la liste des plugins disponible lancez ansible-doc -t connection -l.
Une autre connexion courante est ansible_connection=local qui permet de configurer la machine locale sans avoir besoin d’installer un serveur ssh.
Citons également les connexions ansible_connexion=docker et ansible_connexion=lxd pour configurer des conteneurs linux ainsi que ansible_connexion=winrm pour les serveurs windows
Les questions de sécurités de la connexion se posent bien sûr différemment selon le mode de connexion utilisé (port, authentification, etc.)
Pour débugger les connexions et diagnotiquer leur sécurité on peut afficher les détails de chaque connexion ansible avec le mode de verbosité maximal en utilisant le paramètre -vvvv.
Le principal risque de sécurité lié à Ansible comme avec Docker et l’infrastructure-as-code en général consiste à laisser trainer des secrets (mot de passe, identités de clients, tokens d’API, secrets de chiffrement / migration etc.) dans le code (ou sur les serveurs à des endroits non prévus).
Attention : les dépôts git peuvent cacher des secrets dans leur historique. Pour nettoyer un secret dans un dépôt Git, l’outil le plus courant est BFG : https://rtyley.github.io/bfg-repo-cleaner/
Ansible propose une directive no_log: yes qui permet de désactiver l’affichage des valeurs d’entrée et de sortie d’une tâche.
Il est ainsi possible de limiter la prolifération de données sensibles.
Par exemple, si une tâche change une entrée en base qui contient un mot de passe, no_log: yes est tout indiqué.
Pour éviter de divulguer des secrets par inadvertance, il est possible de gérer les secrets avec des variables d’environnement ou avec un fichier variable externe au projet qui échappera au versionning git, mais ce n’est pas idéal.
Ansible intègre un trousseau de secrets appelé Ansible Vault. Il permet de chiffrer des valeurs variables par variables ou via des fichiers complets. Les valeurs stockées dans le trousseau sont déchiffrées à l’exécution après déverrouillage du trousseau.
ansible-vault create /var/secrets.ymlansible-vault edit /var/secrets.yml ouvre $EDITOR pour changer le fichier de variables.ansible-vault encrypt_file /vars/secrets.yml pour chiffrer un fichier existantansible-vault encrypt_string monmotdepasse permet de chiffrer une valeur avec un mot de passe. le résultat peut être ensuite collé dans un fichier de variables par ailleurs en clair.Pour déchiffrer il est ensuite nécessaire d’ajouter l’option --ask-vault-pass au moment de l’exécution de ansible ou ansible-playbook
Il existe également un mode pour gérer plusieurs mots de passe associés à des identifiants.
L’automatisation Ansible fait d’autant plus sens dans un environnement dynamique d’infrastructures :
Il existe de nombreuses solutions pour intégrer Ansible avec les principaux providers de cloud (modules Ansible, plugins d’API, intégration avec d’autre outils d’Infrastructure-as-Code cloud comme Terraform ou Cloudformation).
Les inventaires que nous avons utilisés jusqu’ici implique d’affecter à la main les adresses IP des différents noeuds de notre infrastructure. Cela devient vite ingérable si celle-ci change souvent.
La solution Ansible pour ne pas gérer les IP et les groupes à la main est appelée inventaire dynamique ou inventory plugin. Un inventaire dynamique est simplement un programme qui renvoie un JSON respectant le format d’inventaire JSON Ansible, généralement en contactant l’API du cloud provider ou une autre source.
$ ./inventory_terraform.py
{
"_meta": {
"hostvars": {
"balancer0": {
"ansible_host": "104.248.194.100"
},
"balancer1": {
"ansible_host": "104.248.204.222"
},
"awx0": {
"ansible_host": "104.248.204.202"
},
"appserver0": {
"ansible_host": "104.248.202.47"
}
}
},
"all": {
"children": [],
"hosts": [
"appserver0",
"awx0",
"balancer0",
"balancer1"
],
"vars": {}
},
"appservers": {
"children": [],
"hosts": [
"balancer0",
"balancer1"
],
"vars": {}
},
"awxnodes": {
"children": [],
"hosts": [
"awx0"
],
"vars": {}
},
"balancers": {
"children": [],
"hosts": [
"appserver0"
],
"vars": {}
}
}%
On peut ensuite appeler ansible-playbook en utilisant ce programme plutôt qu’un fichier statique d’inventaire: ansible-playbook -i inventory_terraform.py configuration.yml
Bonne pratique : Normalement l’information de configuration Ansible doit provenir au maximum de l’inventaire. Ceci est conforme à l’orientation plutôt déclarative d’Ansible et à son exécution descendante (master -> nodes). La méthode à privilégier pour intégrer Ansible à des sources d’information existantes est donc d’utiliser ou développer un plugin d’inventaire.
https://docs.ansible.com/ansible/latest/plugins/inventory.html
On peut cependant alimenter le dictionnaire de variable Ansible au fur et à mesure de l’exécution, en particulier grâce à la directive register et au module set_fact.
Exemple:
# this is just to avoid a call to |default on each iteration
- set_fact:
postconf_d: {}
- name: 'get postfix default configuration'
command: 'postconf -d'
register: postconf_result
changed_when: false
# the answer of the command give a list of lines such as:
# "key = value" or "key =" when the value is null
- name: 'set postfix default configuration as fact'
set_fact:
postconf_d: >
{{ postconf_d | combine(dict([ item.partition('=')[::2]map'trim') ])) }}
loop: postconf_result.stdout_lines
On peut explorer plus facilement la hiérarchie d’un inventaire statique ou dynamique avec la commande:
ansible-inventory --inventory <inventory> --graph
https://docs.ansible.com/ansible/latest/dev_guide/developing_plugins.html
Pour les VPS de base Amazon EC2 : utiliser un plugin d’inventaire AWS et les modules adaptés.
Possibilité 1 : Gérer l’exécution de tâches Ansible et le monitoring Nagios séparément, utiliser le module nagios pour désactiver les alertes Nagios lorsqu’on manipule les ressources monitorées par Nagios.
Possibilité 2 : Laisser le contrôle à Nagios et utiliser un plugin pour que Nagios puisse lancer des plays Ansible en réponse à des évènements sur les sondes.
apt en lançant:$ sudo apt update
$ sudo apt install software-properties-common
$ sudo apt-add-repository --yes --update ppa:ansible/ansible
$ sudo apt install ansible
ansible --version
=> 2.8.x
ansible all -m ping. Que signifie-t-elle ?-vvv pour mettre en mode très verbeux. Ce mode est très efficace pour debugger lorsqu’une erreur inconnue se présente. Que se passe-t-il avec l’inventaire ?ansible en vous connectant à votre machine localhost et en utilisant le module ping.hotelocal ansible_host=127.0.0.1 dans l’inventaire par défaut (le chemin est /etc/ansible/hosts). Et pinguer hotelocal.LXD est une technologie de conteneurs actuellement promue par canonical (ubuntu) qui permet de faire des conteneur linux orientés systèmes plutôt qu’application. Par exemple systemd est disponible à l’intérieur des conteneurs contrairement aux conteneurs Docker.
LXD est déjà installé et initialisé sur notre ubuntu (sinon apt install snapd + snap install lxd + ajouter votre utilisateur courant au group unix lxd).
Il faut cependant l’initialiser avec : lxd init
Cette commande vous pose un certain nombre de questions pour la configuration et vous pouvez garder TOUTES les valeurs par défaut en fait ENTER simplement à chaque question.
Affichez la liste des conteneurs avec lxc list. Aucun conteneur ne tourne.
Maintenant lançons notre premier conteneur centos avec lxc launch images:centos/7/amd64 centos1.
Listez à nouveau les conteneurs lxc.
Ce conteneur est un centos minimal et n’a donc pas de serveur SSH pour se connecter. Pour lancez des commandes dans le conteneur on utilise une commande LXC pour s’y connecter lxc exec <non_conteneur> -- <commande>. Dans notre cas nous voulons lancer bash pour ouvrir un shell dans le conteneur : lxc exec centos1 -- bash.
Nous pouvons installer des logiciels dans le conteneur comme dans une VM. Pour sortir du conteneur on peut simplement utiliser exit.
Un peu comme avec Docker, LXC utilise des images modèles pour créer des conteneurs. Affichez la liste des images avec lxc image list. Trois images sont disponibles l’image centos vide téléchargée et utilisée pour créer centos1 et deux autres images préconfigurée ubuntu_ansible et centos_ansible. Ces images contiennent déjà la configuration nécessaire pour être utilisée avec ansible (SSH + Python + Un utilisateur + une clé SSH).
Supprimez la machine centos1 avec lxc stop centos1 && lxc delete centos1
Pour avoir tous les mêmes images de base générons-les depuis un script pré-installé, dans un terminal lancez :
bash /opt/lxd.sh
Créons à partir des images du remotes un conteneur ubuntu et un autre centos:
lxc launch ubuntu_ansible ubu1
lxc launch centos_ansible centos1
Pour se connecter en SSH nous allons donc utiliser une clé SSH appelée id_stagiaire qui devrait être présente dans votre dossier ~/.ssh/. Vérifiez cela en lançant ls -l /home/stagiaire/.ssh.
Déverrouillez cette clé ssh avec ssh-add ~/.ssh/id_stagiaire et le mot de passe devops101 (le ssh-agent doit être démarré dans le shell pour que cette commande fonctionne si ce n’est pas le cas eval $(ssh-agent)).
Essayez de vous connecter à ubu1 et centos1 en ssh pour vérifier que la clé ssh est bien configurée et vérifiez dans chaque machine que le sudo est configuré sans mot de passe avec sudo -i.
Lorsqu’on développe avec Ansible il est conseillé de le gérer comme un véritable projet de code :
inventory.cfg ou hosts et une configuration locale au projet ansible.cfgNous allons créer un tel projet de code pour la suite du tp1
tp1 sur le Bureau.Open Folder...Un projet Ansible implique généralement une configuration Ansible spécifique décrite dans un fichier ansible.cfg
ansible.cfg avec à l’intérieur:[defaults]
inventory = ./inventory.cfg
roles_path = ./roles
host_key_checking = false # nécessaire pour les labs où l'on créé et supprime des machines constamment avec des signatures SSH changées.
ansible.cfg et ajoutez à l’intérieur notre nouvelle machine hote1.Créez et complétez le fichier inventory.cfg d’après ce modèle:
ubu1 ansible_host=<ip>
[all:vars]
ansible_user=<votre_user>
Ansible cherche la configuration locale dans le dossier courant. Conséquence : on lance généralement toutes les commandes Ansible depuis la racine de notre projet.
Dans le dossier du projet, essayez de relancer la commande ad-hoc ping sur cette machine.
Ansible implique le cas échéant (login avec clé ssh) de déverrouiller la clé ssh pour se connecter à chaque hôte. Lorsqu’on en a plusieurs il est donc nécessaire de la déverrouiller en amont avec l’agent ssh pour ne pas perturber l’exécution des commandes ansible. Pour cela : ssh-add.
Créez un groupe adhoc_lab et ajoutez les deux machines ubu1 et centos1.
ping sur les deux machines.ansible.cfg. Cependant on peut aussi utiliser une connexion par mot de passe et préciser l’utilisateur et le mot de passe dans l’inventaire ou en lançant la commande.En précisant les paramètres de connexion dans le playbook il et aussi possible d’avoir des modes de connexion différents pour chaque machine.
adhoc_lab, centos_hosts et ubuntu_hosts avec deux machines dans chacun. (utilisez pour cela [adhoc_lab:children])[all:vars]
ansible_user=<votre_user>
[ubuntu_hosts]
ubu1 ansible_host=<ip>
[centos_hosts]
centos1 ansible_host=<ip>
[adhoc_lab:children]
ubuntu_hosts
centos_hosts
Dans un inventaire ansible on commence toujours par créer les plus petits sous groupes puis on les rassemble en plus grands groupes.
Nous allons maintenant installer nginx sur les 2 machines. Il y a plusieurs façons d’installer des logiciels grâce à Ansible: en utilisant le gestionnaire de paquets de la distribution ou un gestionnaire spécifique comme pip ou npm. Chaque méthode dispose d’un module ansible spécifique.
apt car centos utilise yum. Pour éviter ce problème on peut utiliser le module package qui permet d’uniformiser l’installation (pour les cas simples).
--become pour devenir root avant d’exécuter la commande (cf élévation de privilège dans le cours2)nginxepel-release sur la machine centos.nginx. Que remarque-t-on ?systemd et l’option --check pour vérifier si le service nginx est démarré sur chacune des 2 machines. Normalement vous constatez que le service est déjà démarré (par défaut) sur la machine ubuntu et non démarré sur la machine centos.L’option --check à vérifier l’état des ressources sur les machines mais sans modifier la configuration`. Relancez la commande précédente pour le vérifier. Normalement le retour de la commande est le même (l’ordre peu varier).
Lancez la commande avec state=stopped : le retour est inversé.
Enlevez le --check pour vous assurer que le service est démarré sur chacune des machines.
Visitez dans un navigateur l’ip d’un des hôtes pour voir la page d’accueil nginx.
Il existe trois façon de lancer des commandes unix avec ansible:
le module command utilise python pour lancez la commande.
le module shell utilise un module python qui appelle un shell pour lancer une commande.
le module raw.
creates pour simuler de l’idempotence.Créez un fichier dans /tmp avec touch et l’un des modules précédents.
Relancez la commande. Le retour est toujours changed car ces modules ne sont pas idempotents.
Relancer l’un des modules shell ou command avec touch et l’option creates pour rendre l’opération idempotente. Ansible détecte alors que le fichier témoin existe et n’exécute pas la commande.
ansible adhoc_lab --become -m "command touch /tmp/file" -a "creates=/tmp/file"
tp2_flask_deployment.ansible.cfg comme précédemment.[defaults]
inventory = ./inventory.cfg
roles_path = ./roles
host_key_checking = false
inventory.cfg.
[all:vars]
ansible_user=<user>
[appservers]
app1 ansible_host=10.x.y.z
app2 ansible_host=10.x.y.z
appservers.ansible all -m ping
Le but de ce projet est de déployer une application flask, c’est a dire une application web python. Le code (très minimal) de cette application se trouve sur github à l’adresse: https://github.com/e-lie/flask_hello_ansible.git.
N’hésitez pas consulter extensivement la documentation des modules avec leur exemple ou d’utiliser la commande de doc ansible-doc <module>
Créons un playbook : ajoutez un fichier flaskhello_deploy.yml avec à l’intérieur:
- hosts: <hotes_cible>
tasks:
- name: ping
ping:
Lancez ce playbook avec la commande ansible-playbook <nom_playbook>.
Commençons par installer les dépendances de cette application. Tous nos serveurs d’application sont sur ubuntu. Nous pouvons donc utiliser le module apt pour installer les dépendances. Il fournit plus d’option que le module package.
Avec le module apt installez les applications: python3-dev, python3-pip, python3-virtualenv, virtualenv, nginx, git. Donnez à cette tâche le nom: ensure basic dependencies are present. Ajoutez, pour devenir root, la directive become: yes au début du playbook.
- name: Ensure apt dependencies are present
apt:
name:
- python3-dev
- python3-pip
- python3-virtualenv
- virtualenv
- nginx
- git
state: present
Lancez ce playbook sans rien appliquer avec la commande ansible-playbook <nom_playbook> --check --diff. La partie --check indique à Ansible de ne faire aucune modification. La partie --diff nous permet d’afficher ce qui changerait à l’application du playbook.
Relancez bien votre playbook à chaque tâche : comme Ansible est idempotent il n’est pas grave en situation de développement d’interrompre l’exécution du playbook et de reprendre l’exécution après un échec.
Ajoutez une tâche systemd pour s’assurer que le service nginx est démarré.
- name: Ensure nginx service started
systemd:
name: nginx
state: started
flask et l’ajouter au groupe www-data. Utilisez bien le paramètre append: yes pour éviter de supprimer des groupes à l’utilisateur. - name: Add the user running webapp
user:
name: "flask"
state: present
append: yes # important pour ne pas supprimer les groupes d'un utilisateur existant
groups:
- "www-data"
Pour déployer le code de l’application deux options sont possibles.
sync qui fait une copie rsync.git.Nous allons utiliser la deuxième option (git) qui est plus cohérente pour le déploiement et la gestion des versions logicielles. Allez voir la documentation comment utiliser ce module.
Utilisez le pour télécharger le code source de l’application (branche master) dans le dossier /home/flask/hello mais en désactivant la mise à jour (au cas ou le code change).
- name: Git clone/update python hello webapp in user home
git:
repo: "https://github.com/e-lie/flask_hello_ansible.git"
dest: /home/flask/hello
version: "master"
clone: yes
update: no
Le langage python a son propre gestionnaire de dépendances pip qui permet d’installer facilement les librairies d’un projet. Il propose également un méchanisme d’isolation des paquets installés appelé virtualenv. Normalement installer les dépendances python nécessite 4 ou 5 commandes shell.
La liste de nos dépendances est listée dans le fichier requirements.txt à la racine du dossier d’application.
Nous voulons installer ces dépendances dans un dossier venv également à la racine de l’application.
Nous voulons installer ces dépendances en version python3 avec l’argument virtualenv_python: python3.
Avec ces informations et la documentation du module pip installez les dépendances de l’application.
Notre application sera executée en tant qu’utilisateur flask pour des raisons de sécurité. Pour cela le dossier doit appartenir à cet utilisateur or il a été créé en tant que root (à cause du become: yes de notre playbook).
file qui change le propriétaire du dossier de façon récursive. - name: Change permissions of app directory
file:
path: /home/flask/hello
state: directory
owner: "flask"
recurse: true
Notre application doit tourner comme c’est souvent le cas en tant que service (systemd). Pour cela nous devons créer un fichier service adapté hello.service dans le le dossier /etc/systemd/system/.
Ce fichier est un fichier de configuration qui doit contenir le texte suivant:
[Unit]
Description=Gunicorn instance to serve hello
After=network.target
[Service]
User=flask
Group=www-data
WorkingDirectory=/home/flask/hello
Environment="PATH=/home/flask/hello/venv/bin"
ExecStart=/home/flask/hello/venv/bin/gunicorn --workers 3 --bind unix:hello.sock -m 007 app:app
[Install]
WantedBy=multi-user.target
Pour gérer les fichier de configuration on utilise généralement le module template qui permet à partir d’un fichier modèle situé dans le projet ansible de créer dynamiquement un fichier de configuration adapté sur la machine distante.
Créez un dossier templates, avec à l’intérieur le fichier app.service.j2 contenant le texte précédent.
Utilisez le module template pour le copier au bon endroit avec le nom hello.service.
Utilisez ensuite systemd pour démarrer ce service (state: restarted ici pour le cas ou le fichier à changé).
hello.test.conf dans le dossier /etc/nginx/sites-available à partir du fichier modèle:nginx.conf.j2
server {
listen 80;
server_name hello.test;
location / {
include proxy_params;
proxy_pass http://unix:/home/flask/hello/hello.sock;
}
}
Utilisez file pour créer un lien symbolique de ce fichier dans /etc/nginx/sites-enabled (avec l’option force:yes pour écraser le cas échéant).
Ajoutez une tâche pour supprimer le site /etc/nginx/sites-enabled/default.
Ajouter une tâche de redémarrage de nginx.
Ajoutez hello.test dans votre fichier /etc/hosts pointant sur l’ip d’un des serveur d’application.
Visitez l’application dans un navigateur et debugger le cas échéant.
flaskhello_deploy.yml
Ajoutons des variables pour gérer dynamiquement les paramètres de notre déploiement:
Ajoutez une section vars: avant la section tasks: du playbook.
Mettez dans cette section la variable suivante (dictionnaire):
app:
name: hello
user: flask
domain: hello.test
Remplacez dans le playbook précédent et les deux fichiers de template:
hello par {{ app.name }}flask par {{ app.user }}hello.test par {{ app.domain }}Relancez le playbook : toutes les tâches devraient renvoyer ok à part les “restart” car les valeurs sont identiques.
tp2_before_handlers_correction avec git checkout tp2_before_handlers_correction.Le dépôt contient également les corrigés du TP3 et TP4 dans d’autre branches.
Vous pouvez consultez la correction également directement sur le site de github.
Pour le moment dans notre playbook, les deux tâches de redémarrage de service sont en mode restarted c’est à dire qu’elles redémarrent le service à chaque exécution (résultat: changed) et ne sont donc pas idempotentes. En imaginant qu’on lance ce playbook toutes les 15 minutes dans un cron pour stabiliser la configuration, on aurait un redémarrage de nginx 4 fois par heure sans raison.
On désire plutôt ne relancer/recharger le service que lorsque la configuration conrespondante a été modifiée. c’est l’objet des tâches spéciales nommées handlers.
Ajoutez une section handlers: à la suite
Déplacez la tâche de redémarrage/reload de nginx dans cette section et mettez comme nom reload nginx.
Ajoutez aux deux tâches de modification de la configuration la directive notify: <nom_du_handler>.
Testez votre playbook. Il devrait être idempotent sauf le restart de hello.service.
Testez le handler en ajoutant un commentaire dans le fichier de configuration nginx.conf.j2.
- name: template nginx site config
template:
src: templates/nginx.conf.j2
dest: /etc/nginx/sites-available/{{ app.domain }}.conf
notify: reload nginx
...
handlers:
- name: reload nginx
systemd:
name: "nginx"
state: reloaded
# => penser aussi à supprimer la tâche de restart de nginx précédente
Plutôt qu’une variable app unique on voudrait fournir au playbook une liste d’application à installer (liste potentiellement définie durant l’exécution).
Identifiez dans le playbook précédent les tâches qui sont exactement communes aux deux installations.
Créez un nouveau fichier deploy_app_tasks.yml et copier à l’intérieur la liste de toutes les autres tâches mais sans les handlers que vous laisserez à la fin du playbook.
Ce nouveau fichier n’est pas à proprement parler un playbook mais une liste de tâches. utilisez include_tasks: pour importer cette liste de tâche à l’endroit ou vous les avez supprimées.
Vérifiez que le playbook fonctionne et est toujours idempotent.
Ajoutez une tâche debug: msg={{ app }} au début du playbook pour visualiser le contenu de la variable.
Ensuite remplacez la variable app par une liste flask_apps de deux dictionnaires (avec name, domain, user différents les deux dictionnaires et repository et version identiques).
flask_apps:
- name: hello
domain: "hello.test"
user: "flask1"
version: master
repository: https://github.com/e-lie/flask_hello_ansible.git
- name: hello2
domain: "hello2.test"
user: "flask2"
version: master
repository: https://github.com/e-lie/flask_hello_ansible.git
Utilisez les directives loop et loop_control+loop_var sur la tâche include_tasks pour inclure les tâches pour chacune des deux applications.
Créez le dossier group_vars et déplacez le dictionnaire flask_apps dans un fichier group_vars/appservers.yml. Comme son nom l’indique ce dossier permet de définir les variables pour un groupe de serveurs dans un fichier externe.
Testez en relançant le playbook que le déplacement des variables est pris en compte correctement.
tp2_correction avec git checkout tp2_correction.Le dépôt contient également les corrigés du TP3 et TP4 dans d’autre branches.
Vous pouvez consultez la correction également directement sur le site de github.
Pour ceux ou celles qui sont allé-es vite, vous pouvez tenter de créer une nouvelle version de votre playbook portable entre CentOS et ubuntu. Pour cela utilisez la directive when: ansible_os_family == 'Debian' ou RedHat.
Essayez de déployer une version plus complexe d’application flask avec une base de donnée mysql: https://github.com/miguelgrinberg/microblog/tree/v0.17
Il s’agit de l’application construite au fur et à mesure dans un super tutoriel Python sur Flask. Ce chapitre indique comment déployer l’application sur linux.
tp3_provisionner_roles.Dans notre infra virtuelle, nous avons trois machines dans deux groupes. Quand notre lab d’infra grossit il devient laborieux de créer les machines et affecter les ip à la main. En particulier détruire le lab et le reconstruire est pénible. Nous allons pour cela introduire un playbook de provisionning qui va créer les conteneurs lxd en définissant leur ip à partir de l’inventaire.
[all:vars]
ansible_user=<votre_user>
[appservers]
app1 ansible_host=10.x.y.121 container_image=ubuntu_ansible node_state=started
app2 ansible_host=10.x.y.122 container_image=ubuntu_ansible node_state=started
[dbservers]
db1 ansible_host=10.x.y.131 container_image=ubuntu_ansible node_state=started
Remplacez x et y dans l’adresse IP par celle fournies par votre réseau virtuel lxd (faites lxc list et copier simplement les deux chiffres du milieu des adresses IP)
Ajoutez un playbook provision_lxd_infra.yml dans un dossier provisionners contenant:
- hosts: localhost
connection: local
tasks:
- name: Setup linux containers for the infrastructure simulation
lxd_container:
name: "{{ item }}"
state: "{{ hostvars[item]['node_state'] }}"
source:
type: image
alias: "{{ hostvars[item]['container_image'] }}"
profiles: ["default"]
config:
security.nesting: 'true'
security.privileged: 'false'
devices:
# configure network interface
eth0:
type: nic
nictype: bridged
parent: lxdbr0
# get ip address from inventory
ipv4.address: "{{ hostvars[item].ansible_host }}"
# Comment following line if you installed lxd using apt
url: unix:/var/snap/lxd/common/lxd/unix.socket
wait_for_ipv4_addresses: true
timeout: 600
register: containers
loop: "{{ groups['all'] }}"
# Uncomment following if you want to populate hosts file pour container local hostnames
# AND launch playbook with --ask-become-pass option
# - name: Config /etc/hosts file accordingly
# become: yes
# lineinfile:
# path: /etc/hosts
# regexp: ".*{{ item }}$"
# line: "{{ hostvars[item].ansible_host }} {{ item }}"
# state: "present"
# loop: "{{ groups['all'] }}"
Etudions le playbook (explication démo).
Lancez le playbook avec sudo car lxd se contrôle en root sur localhost: sudo ansible-playbook provision_lxd_infra (c’est le seul cas exceptionnel ou ansible-playbook doit être lancé avec sudo, pour les autre playbooks ce n’est pas le cas)
Lancez lxc list pour afficher les nouvelles machines de notre infra et vérifier que le serveur de base de données a bien été créé.
roles dans lequel seront rangés tous les rôles (c’est une convention Ansible à respecter).flaskapp dans roles.flaskapp
├── defaults
│ └── main.yml
├── handlers
│ └── main.yml
├── tasks
│ ├── deploy_app_tasks.yml
│ └── main.yml
└── templates
├── app.service.j2
└── nginx.conf.j2
defaults/main.yml permet de définir des valeurs par défaut pour les variables du rôle. Mettez à l’intérieur une application par défaut :flask_apps:
- name: defaultflask
domain: defaultflask.test
repository: https://github.com/e-lie/flask_hello_ansible.git
version: master
user: defaultflask
Ces valeurs seront écrasées par celles fournies dans le dossier group_vars (la liste de deux applications du TP2). Elle est présente pour que le rôle fonctionne même en l’absence de variable (valeurs de fallback).
Copiez les tâches (juste la liste de tirets sans l’intitulé de section tasks:) contenues dans le playbook appservers dans le fichier tasks/main.yml.
De la même façon, copiez le handler dans handlers/main.yml sans l’intitulé handlers:.
Copiez également le fichier deploy_flask_tasks.yml dans le dossier tasks.
Déplacez vos deux fichiers de template dans le dossier templates du rôle (et non celui à la racine que vous pouvez supprimer).
Pour appeler notre nouveau rôle, supprimez les sections tasks: et handlers: du playbook appservers.yml et ajoutez à la place:
roles:
- flaskapp
appservers.yml et debuggez le résultat le cas échéant.tp3_correction avec git checkout tp3_correction.Il contient également les corrigés du TP2 et TP4 dans d’autres branches.
Essayez différents exemples de projets de Geerlingguy accessibles sur GitHub à l’adresse https://github.com/geerlingguy/ansible-for-devops.
tp4_correction avec git checkout tp4_correction.Pour configurer notre infrastructure:
Installez les rôles avec ansible-galaxy install -r roles/requirements.yml -p roles.
Si vous n’avez pas fait la partie Terraform:
./inventory.cfg comme pour les TP précédentssudo ansible-playbook provisionner/provision_lxd_infra.ymlLancez le playbook global site.yml
Utilisez la commande ansible-inventory --graph pour afficher l’arbre des groupes et machines de votre inventaire
Utilisez la de même pour récupérer l’ip du balancer0 (ou balancer1) avec : ansible-inventory --host=balancer0
Ajoutez hello.test et hello2.test dans /etc/hosts pointant vers l’ip de balancer0.
Chargez les pages hello.test et hello2.test.
Observons ensemble l’organisation du code Ansible de notre projet.
balancers.ymlupgrade_apps.yml permet de mettre à jour l’application en respectant sa haute disponibilité. Il s’agit d’une opération d’orchestration simple en les 3 serveurs de notre infrastructure.serial qui permet de d’exécuter séquentiellement un play sur un fraction des serveurs d’un groupe (ici 1 à la fois parmis les 2).delegate qui permet d’exécuter une tâche sur une autre machine que le groupe initialement ciblé. Cette directive est au coeur des possibilités d’orchestration Ansible en ce qu’elle permet de contacter un autre serveur ( déplacement latéral et non pas master -> node ) pour récupérer son état ou effectuer une modification avant de continuer l’exécution et donc de coordonner des opérations.exclude_backend.yml qui permet de sortir un backend applicatif du pool. Il s’utilise avec des variables en ligne de commandeDésactivez le noeud qui vient de vous servir la page en utilisant le playbook exclude_backend.yml:
ansible-playbook --extra-vars="backend_name=<noeud a desactiver> backend_state=disabled" playbooks/exclude_backend.yml
Rechargez la page: vous constatez que c’est l’autre backend qui a pris le relais.
Nous allons maintenant mettre à jour
Créer et manipuler des conteneurs
![]()
Une abstraction qui ouvre de nouvelles possibilités pour la manipulation logicielle.
Permet de standardiser et de contrôler la livraison et le déploiement.
On compare souvent les conteneurs aux machines virtuelles. Mais ce sont de grosses simplifications parce qu’on en a un usage similaire : isoler des programmes dans des “contextes”. Une chose essentielle à retenir sur la différence technique : les conteneurs utilisent les mécanismes internes du _kernel de l’OS Linux_ tandis que les VM tentent de communiquer avec l’OS (quel qu’il soit) pour directement avoir accès au matériel de l’ordinateur.
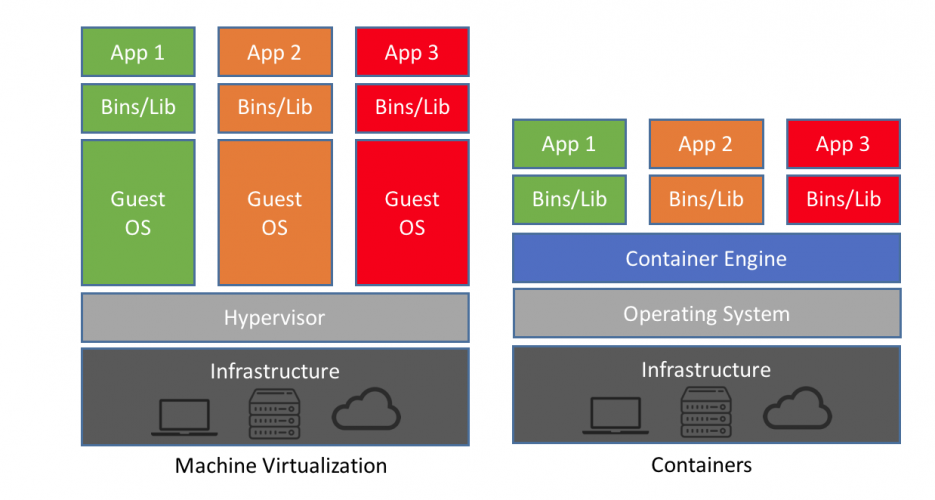
VM : une abstraction complète pour simuler des machines
conteneur : un découpage dans Linux pour séparer des ressources (accès à des dossiers spécifiques sur le disque, accès réseau).
Les deux technologies peuvent utiliser un système de quotas pour l’accès aux ressources matérielles (accès en lecture/écriture sur le disque, sollicitation de la carte réseau, du processeur)
Si l’on cherche la définition d’un conteneur :
C’est un groupe de processus associé à un ensemble de permissions.
L’imaginer comme une “boîte” est donc une allégorie un peu trompeuse, car ce n’est pas de la virtualisation (= isolation au niveau matériel).
Les conteneurs mettent en œuvre un vieux concept d’isolation des processus permis par la philosophie Unix du “tout est fichier”.
chroot, jail, les 6 namespaces et les cgroupschrootchroot [change root : changer de racine], présent dans les systèmes UNIX depuis longtemps (1979 !) :
“Comme tout est fichier, changer la racine d’un processus, c’est comme le faire changer de système”.
jailjail est introduit par FreeBSD en 2002 pour compléter chroot et qui permet pour la première fois une isolation réelle (et sécurisée) des processus.
chroot ne s’occupait que de l’isolation d’un process par rapport au système de fichiers :
En 2005, Sun introduit les conteneurs Solaris décrits comme un « chroot sous stéroïdes » : comme les jails de FreeBSD
Les namespaces, un concept informatique pour parler simplement de…
jail était une façon de compléter chroot, pour FreeBSD.
Pour Linux, ce concept est repris via la mise en place de namespaces Linux
Les conteneurs ne sont finalement que plein de fonctionnalités Linux saucissonnées ensemble de façon cohérente.
Les namespaces correspondent à autant de types de compartiments nécessaires dans l’architecture Linux pour isoler des processus.
Pour la culture, 6 types de namespaces :
Après, il reste à s’occuper de limiter la capacité d’un conteneur à agir sur les ressources matérielles :
En 2005, Google commence le développement des cgroups : une façon de tagger les demandes de processeur et les appels systèmes pour les grouper et les isoler.
:(){ : | :& }; :
Ceci est une fork bomb. Dans un conteneur non privilégié, on bloque tout Docker, voire tout le système sous-jacent, en l’empêchant de créer de nouveaux processus.
Pour éviter cela il faudrait limiter la création de processus via une option kernel.
Ex: docker run -it --ulimit nproc=3 --name fork-bomb bash
L’isolation des conteneurs n’est donc ni magique, ni automatique, ni absolue ! Correctement paramétrée, elle est tout de même assez robuste, mature et testée.
On revient à notre définition d’un conteneur :
1 container = 1 groupe de process Linux
- des namespaces (séparation entre ces groups)
- des cgroups (quota en ressources matérielles)
En 2008 démarre le projet LXC qui chercher à rassembler :
Originellement, Docker était basé sur LXC. Il a depuis développé son propre assemblage de ces 3 mécanismes.
En 2013, Docker commence à proposer une meilleure finition et une interface simple qui facilite l’utilisation des conteneurs LXC.
Puis il propose aussi son cloud, le Docker Hub pour faciliter la gestion d’images toutes faites de conteneurs.
Au fur et à mesure, Docker abandonne le code de LXC (mais continue d’utiliser le chroot, les cgroups et namespaces).
Le code de base de Docker (notamment runC) est open source : l'Open Container Initiative vise à standardiser et rendre robuste l’utilisation de containers.
Docker permet de faire des “quasi-machines” avec des performances proches du natif.
VM et conteneurs proposent une flexibilité de manipulation des ressources de calcul mais les machines virtuelles sont trop lourdes pour être multipliées librement :
Les VM se rapprochent plus du concept de “boite noire”: l’isolation se fait au niveau du matériel et non au niveau du noyau de l’OS.
même si une faille dans l’hyperviseur reste possible car l’isolation n’est pas qu’uniquement matérielle
Les VM sont-elles “plus lentes” ? Pas forcément.
La comparaison VM / conteneurs est un thème extrêmement vaste et complexe.
Docker est pensé dès le départ pour faire des conteneurs applicatifs :
isoler les modules applicatifs.
gérer les dépendances en les embarquant dans le conteneur.
se baser sur l'immutabilité : la configuration d’un conteneur n’est pas faite pour être modifiée après sa création.
avoir un cycle de vie court -> logique DevOps du “bétail vs. animal de compagnie”
Docker modifie beaucoup la “logistique” applicative.
uniformisation face aux divers langages de programmation, configurations et briques logicielles
installation sans accroc et automatisation beaucoup plus facile
permet de simplifier l'intégration continue, la livraison continue et le déploiement continu
rapproche le monde du développement des opérations (tout le monde utilise la même technologie)
Permet l’adoption plus large de la logique DevOps (notamment le concept d’infrastructure as code)
Docker est la technologie ultra-dominante sur le marché de la conteneurisation
LXC existe toujours et est très agréable à utiliser, notamment avec LXD (développé par Canonical, l’entreprise derrière Ubuntu).
Apache Mesos : un logiciel de gestion de cluster qui permet de se passer de Docker, mais propose quand même un support pour les conteneurs OCI (Docker) depuis 2016.
Podman : une alternative à Docker qui utilise la même syntaxe que Docker pour faire tourner des conteneurs OCI (Docker) qui propose un mode rootless et daemonless intéressant.
systemd-nspawn : technologie de conteneurs isolés proposée par systemd
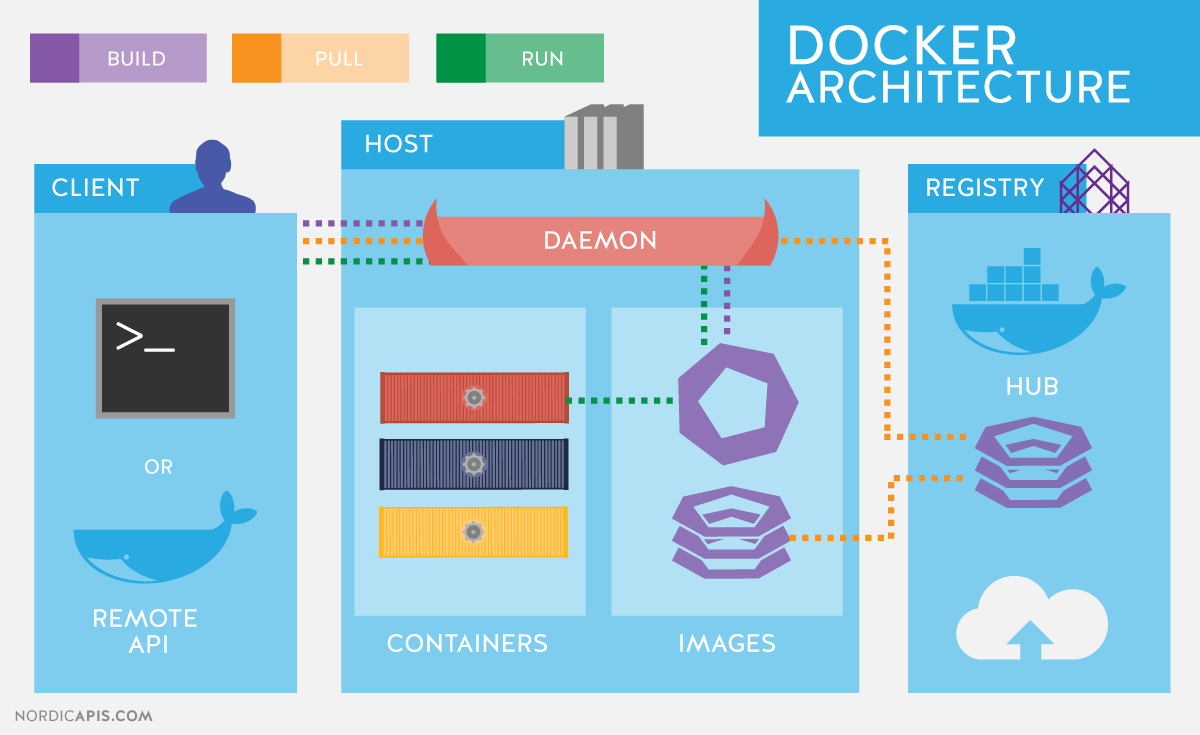
Deux concepts centraux :
Autres concepts primordiaux :
Docker Compose : Un outil pour décrire des applications multiconteneurs.
Docker Machine : Un outil pour gérer le déploiement Docker sur plusieurs machines depuis un hôte.
Docker Hub : Le service d’hébergement d’images proposé par Docker Inc. (le registry officiel)
Docker Engine pour lancer des commandes docker
Docker Compose pour lancer des application multiconteneurs
Portainer, un GUI Docker
VirtualBox pour avoir une VM Linux quand on est sur Windows
Docker est basé sur le noyau Linux :
Quatre possibilités :
Solution WSL2 : on utilise Docker Desktop WSL2:
Solution Windows : on utilise Docker Desktop for Windows:
Solution VirtualBox : on utilise Docker Engine dans une VM Linux
Solution legacy : on utilise Docker Toolbox pour configurer Docker avec le driver VirtualBox :
Pas de virtualisation nécessaire car Docker (le Docker Engine) utilise le noyau du système natif.
On peut l’installer avec le gestionnaire de paquets de l’OS mais cette version peut être trop ancienne.
Sur Ubuntu ou CentOS la méthode conseillée est d’utiliser les paquets fournis dans le dépôt officiel Docker (vous pouvez avoir des surprises avec la version snap d’Ubuntu).
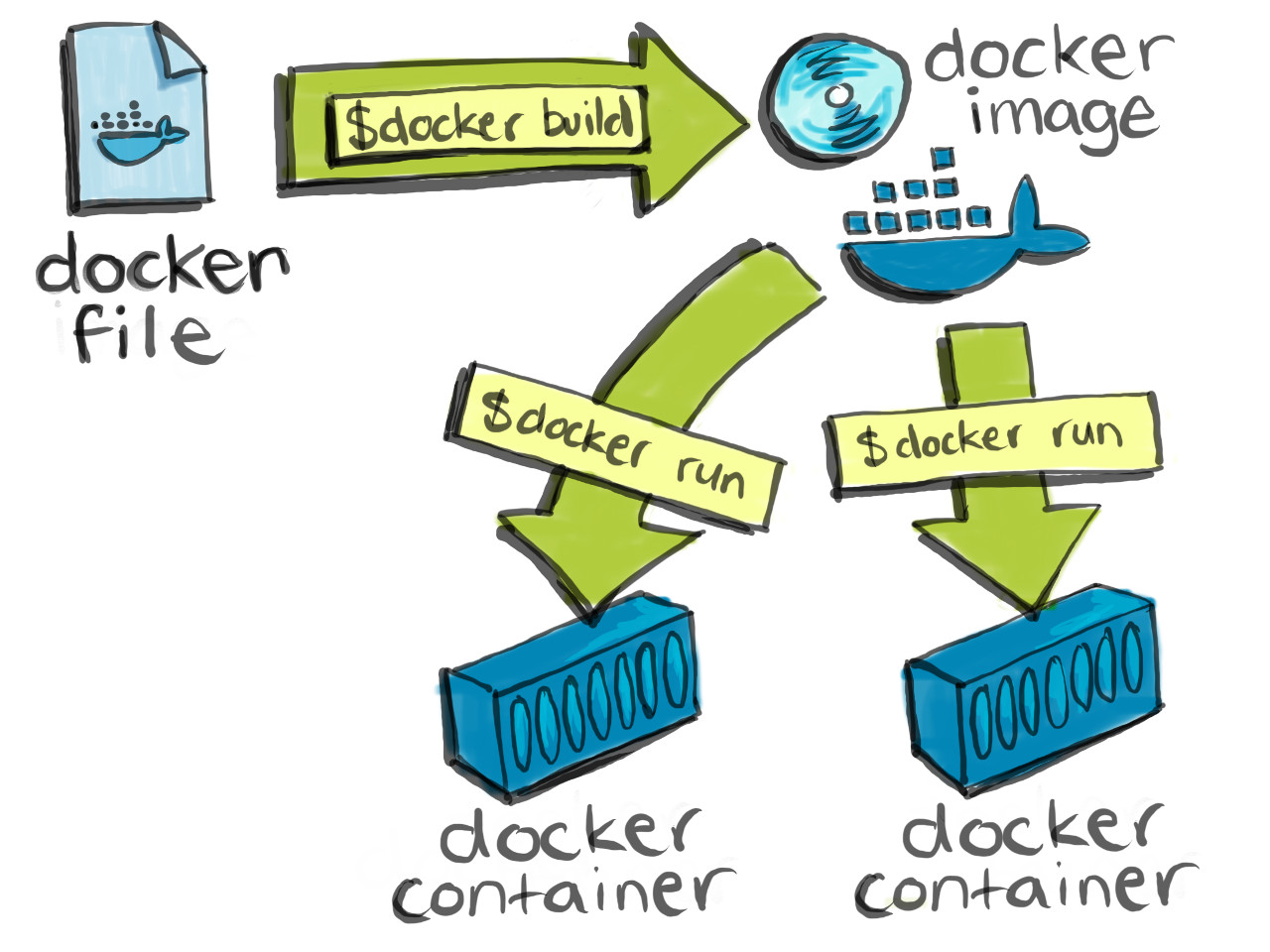 Docker possède à la fois un module pour lancer les applications (runtime) et un outil de build d’application.
Docker possède à la fois un module pour lancer les applications (runtime) et un outil de build d’application.
Pour lister les images on utilise :
docker images
docker image ls
Docker fonctionne avec des sous-commandes et propose de grandes quantités d’options pour chaque commande.
Utilisez --help au maximum après chaque commande, sous-commande ou sous-sous-commandes
docker image --help
docker info # affiche plein d'information sur l'engine avec lequel vous êtes en contact
docker ps # affiche les conteneurs en train de tourner
docker ps -a # affiche également les conteneurs arrêtés

docker run [-d] [-p port_h:port_c] [-v dossier_h:dossier_c] <image> <commande>
créé et lance le conteneur
--name-d permet* de lancer le conteneur en mode daemon ou détaché et libérer le terminal-p permet de mapper un port réseau entre l’intérieur et l’extérieur du conteneur, typiquement lorsqu’on veut accéder à l’application depuis l’hôte.-v permet de monter un volume partagé entre l’hôte et le conteneur.--rm (comme remove) permet de supprimer le conteneur dès qu’il s’arrête.-it permet de lancer une commande en mode interactif (un terminal comme bash).-a (ou --attach) permet de se connecter à l’entrée-sortie du processus dans le container.Le démarrage d’un conteneur est lié à une commande.
Si le conteneur n’a pas de commande, il s’arrête dès qu’il a fini de démarrer
docker run debian # s'arrête tout de suite
docker run debian echo 'attendre 10s' && sleep 10 # s'arrête après 10s
docker run créé un nouveau conteneur à chaque fois.
docker stop <nom_ou_id_conteneur> # ne détruit pas le conteneur
docker start <nom_ou_id_conteneur> # le conteneur a déjà été créé
docker start --attach <nom_ou_id_conteneur> # lance le conteneur et s'attache à la sortie standard
Les conteneurs sont plus que des processus, ce sont des boîtes isolées grâce aux namespaces et cgroups
Depuis l’intérieur d’un conteneur, on a l’impression d’être dans un Linux autonome.
Plus précisément, un conteneur est lié à un système de fichiers (avec des dossiers /bin, /etc, /var, des exécutables, des fichiers…), et possède des métadonnées (stockées en json quelque part par Docker)
Les utilisateurs Unix à l’intérieur du conteneur ont des UID et GID qui existent classiquement sur l’hôte mais ils peuvent correspondre à un utilisateur Unix sans droits sur l’hôte si on utilise les user namespaces.
La commande docker exec permet d’exécuter une commande à l’intérieur du conteneur s’il est lancé.
Une utilisation typique est d’introspecter un conteneur en lançant bash (ou sh).
docker exec -it <conteneur> /bin/bash
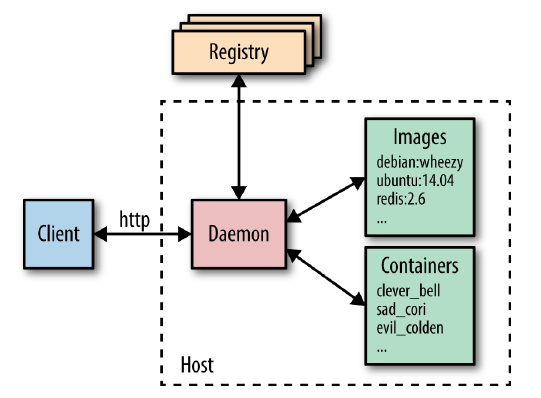
Une des forces de Docker vient de la distribution d’images :
pas besoin de dépendances, on récupère une boîte autonome
pas besoin de multiples versions en fonction des OS
Dans ce contexte un élément qui a fait le succès de Docker est le Docker Hub : hub.docker.com
Il s’agit d’un répertoire public et souvent gratuit d’images (officielles ou non) pour des milliers d’applications pré-configurées.
On peut y chercher et trouver presque n’importe quel logiciel au format d’image Docker.
Il suffit pour cela de chercher l’identifiant et la version de l’image désirée.
Puis utiliser docker run [<compte>/]<id_image>:<version>
La partie compte est le compte de la personne qui a poussé ses images sur le Docker Hub. Les images Docker officielles (ubuntu par exemple) ne sont pas liées à un compte : on peut écrire simplement ubuntu:focal.
On peut aussi juste télécharger l’image : docker pull <image>
On peut également y créer un compte gratuit pour pousser et distribuer ses propres images, ou installer son propre serveur de distribution d’images privé ou public, appelé registry.
Accédez à votre VM via l’interface Guacamole
Pour accéder au copier-coller de Guacamole, il faut appuyer sur Ctrl+Alt+Shift et utiliser la zone de texte qui s’affiche (réappuyer sur Ctrl+Alt+Shift pour revenir à la VM).
Pour installer Docker, suivez la documentation officielle pour installer Docker sur Ubuntu, depuis “Install using the repository” jusqu’aux deux commandes sudo apt-get update et sudo apt-get install docker-ce docker-ce-cli containerd.io.
curl -sSL https://get.docker.com | sudo shLancez sudo docker run hello-world. Bien lire le message renvoyé (le traduire sur Deepl si nécessaire). Que s’est-il passé ?
Il manque les droits pour exécuter Docker sans passer par sudo à chaque fois.
rootdockerusermod -aG docker <user> (en remplaçant <user> par ce qu’il faut)sudo reboot puis reconnectez-vous avec Guacamole pour que la modification sur les groupes prenne effet.bash en copiant les commandes suivantes :sudo apt update
sudo apt install bash-completion curl
sudo mkdir /etc/bash_completion.d/
sudo curl -L https://raw.githubusercontent.com/docker/docker-ce/master/components/cli/contrib/completion/bash/docker -o /etc/bash_completion.d/docker.sh
sudo curl -L https://raw.githubusercontent.com/docker/compose/1.24.1/contrib/completion/bash/docker-compose -o /etc/bash_completion.d/docker-compose
Important: Vous pouvez désormais appuyer sur la touche pour utiliser l’autocomplétion quand vous écrivez des commandes Docker
docker info # affiche plein d'information sur l'engine avec lequel vous êtes en contact
docker ps # affiche les conteneurs en train de tourner
docker ps -a # affiche également les conteneurs arrêtés
docker run : https://docs.docker.com/engine/reference/run/Mentalité :
 Il faut aussi prendre l’habitude de bien lire ce que la console indique après avoir passé vos commandes.
Il faut aussi prendre l’habitude de bien lire ce que la console indique après avoir passé vos commandes.
Avec l’aide du support et de --help, et en notant sur une feuille ou dans un fichier texte les commandes utilisées :
Lancez un conteneur Debian (docker run puis les arguments nécessaires, cf. l’aide --help) en mode détaché avec la commande echo "Debian container". Rien n’apparaît. En effet en mode détaché la sortie standard n’est pas connectée au terminal.
Lancez docker logs avec le nom ou l’id du conteneur. Vous devriez voir le résultat de la commande echo précédente.
Lancez un conteneur debian en mode détaché avec la commande sleep 3600
Réaffichez la liste des conteneurs qui tournent
Tentez de stopper le conteneur, que se passe-t-il ?
docker stop <conteneur>
NB: On peut désigner un conteneur soit par le nom qu’on lui a donné, soit par le nom généré automatiquement, soit par son empreinte (toutes ces informations sont indiquées dans un docker ps ou docker ps -a). L’autocomplétion fonctionne avec les deux noms.
sleep 3600 en mode détaché).debian_containerLe nom d’un conteneur doit être unique (à ne pas confondre avec le nom de l’image qui est le modèle utilisé à partir duquel est créé le conteneur).
debian2docker run debian -d --name debian2 sleep 500
-i -t) avec la commande /bin/bash et le nom debian_interactif.pull).docker pull nginx
docker run --name "test_nginx" nginx
Ce conteneur n’est pas très utile, car on a oublié de configurer un port ouvert.
nginx créé(s).nginx avec cette fois-ci le port correctement configuré dès le début pour pouvoir visiter votre Nginx en local.docker run -p 8080:80 --name "test2_nginx" nginx # la syntaxe est : port_hote:port_container
On peut lancer des logiciels plus ambitieux, comme par exemple Funkwhale, une sorte d’iTunes en web qui fait aussi réseau social :
docker run --name funky_conteneur -p 80:80 funkwhale/all-in-one:1.0.1
Vous pouvez visiter ensuite ce conteneur Funkwhale sur le port 80 (après quelques secondes à suivre le lancement de l’application dans les logs) ! Mais il n’y aura hélas pas de musique dedans :(
Attention à ne jamais lancer deux containers connectés au même port sur l’hôte, sinon cela échouera !
docker rm -f funky_conteneur
8080 à partir de l’image officielle de Wordpress du Docker HubNous pouvons accéder au Wordpress, mais il n’a pas encore de base MySQL configurée. Ce serait un peu dommage de configurer cette base de données à la main. Nous allons configurer cela à partir de variables d’environnement et d’un deuxième conteneur créé à partir de l’image mysql.
Depuis Ubuntu:
docker network create wordpress
Cherchez le conteneur mysql version 5.7 sur le Docker Hub.
Utilisons des variables d’environnement pour préciser le mot de passe root, le nom de la base de données et le nom d’utilisateur de la base de données (trouver la documentation sur le Docker Hub).
Il va aussi falloir définir un nom pour ce conteneur
inspectez le conteneur MySQL avec docker inspect
Faites de même avec la documentation sur le Docker Hub pour préconfigurer l’app Wordpress.
En plus des variables d’environnement, il va falloir le mettre dans le même réseau, et exposer un port
regardez les logs du conteneur Wordpress avec docker logs
visitez votre app Wordpress et terminez la configuration de l’application : si les deux conteneurs sont bien configurés, on ne devrait pas avoir à configurer la connexion à la base de données
avec docker exec, visitez votre conteneur Wordpress. Pouvez-vous localiser le fichier wp-config.php ? Une fois localisé, utilisez docker cp pour le copier sur l’hôte.
Lancez la commande docker ps -aq -f status=exited. Que fait-elle ?
Combinez cette commande avec docker rm pour supprimer tous les conteneurs arrêtés (indice : en Bash, une commande entre les parenthèses de “$()” est exécutée avant et utilisée comme chaîne de caractère dans la commande principale)
S’il y a encore des conteneurs qui tournent (docker ps), supprimez un des conteneurs restants en utilisant l’autocomplétion et l’option adéquate
Listez les images
Supprimez une image
Que fait la commande docker image prune -a ?
docker export votre_conteneur -o conteneur.tar, puis tar -C conteneur_decompresse -xvf conteneur.tar pour décompresser un conteneur Docker, explorez (avec l’explorateur de fichiers par exemple) jusqu’à trouver l’exécutable principal contenu dans le conteneur.Portainer est un portail web pour gérer une installation Docker via une interface graphique. Il va nous faciliter la vie.
docker volume create portainer_data
docker run --detach --name portainer \
-p 9000:9000 \
-v portainer_data:/data \
-v /var/run/docker.sock:/var/run/docker.sock \
portainer/portainer-ce
Remarque sur la commande précédente : pour que Portainer puisse fonctionner et contrôler Docker lui-même depuis l’intérieur du conteneur il est nécessaire de lui donner accès au socket de l’API Docker de l’hôte grâce au paramètre --mount ci-dessus.
Visitez ensuite la page http://localhost:9000 ou l’adresse IP publique de votre serveur Docker sur le port 9000 pour accéder à l’interface.
il faut choisir l’option “local” lors de la configuration
Créez votre user admin et choisir un mot de passe avec le formulaire.
Explorez l’interface de Portainer.
Créez un conteneur.
Jusqu’ici nous avons utilisé des images toutes prêtes.
Une des fonctionnalités principales de Docker est de pouvoir facilement construire des images à partir d’un simple fichier texte : le Dockerfile.
Un image Docker ressemble un peu à une VM car on peut penser à un Linux “freezé” dans un état.
En réalité c’est assez différent : il s’agit uniquement d’un système de fichier (par couches ou layers) et d’un manifeste JSON (des méta-données).
Les images sont créés en empilant de nouvelles couches sur une image existante grâce à un système de fichiers qui fait du union mount.
Chaque nouveau build génère une nouvelle image dans le répertoire des images (/var/lib/docker/images) (attention ça peut vite prendre énormément de place)
On construit les images à partir d’un fichier Dockerfile en décrivant procéduralement (étape par étape) la construction.

FROM debian:latest
RUN apt update && apt install htop
CMD ['sleep 1000']
docker build [-t tag] [-f dockerfile] <build_context>
généralement pour construire une image on se place directement dans le dossier avec le Dockerfile et les élements de contexte nécessaire (programme, config, etc), le contexte est donc le caractère ., il est obligatoire de préciser un contexte.
exemple : docker build -t mondebian .
Le Dockerfile est un fichier procédural qui permet de décrire l’installation d’un logiciel (la configuration d’un container) en enchaînant des instructions Dockerfile (en MAJUSCULE).
Exemple:
# our base image
FROM alpine:3.5
# Install python and pip
RUN apk add --update py2-pip
# upgrade pip
RUN pip install --upgrade pip
# install Python modules needed by the Python app
COPY requirements.txt /usr/src/app/
RUN pip install --no-cache-dir -r /usr/src/app/requirements.txt
# copy files required for the app to run
COPY app.py /usr/src/app/
COPY templates/index.html /usr/src/app/templates/
# tell the port number the container should expose
EXPOSE 5000
# run the application
CMD ["python", "/usr/src/app/app.py"]
FROMRUNADDCMDDockerfile : elle permet de préciser la commande par défaut lancée à la création d’une instance du conteneur avec docker run. on l’utilise avec une liste de paramètresCMD ["echo 'Conteneur démarré'"]
ENTRYPOINTENTRYPOINT ["/usr/bin/python3"]
CMD et ENTRYPOINTRUN qui exécute une commande Bash uniquement pendant la construction de l’image.L’instruction CMD a trois formes :
CMD ["executable","param1","param2"] (exec form, forme à préférer)CMD ["param1","param2"] (combinée à une instruction ENTRYPOINT)CMD command param1 param2 (shell form)Si l’on souhaite que notre container lance le même exécutable à chaque fois, alors on peut opter pour l’usage d'ENTRYPOINT en combination avec CMD.
ENVHEALTHCHECKHEALTHCHECK permet de vérifier si l’app contenue dans un conteneur est en bonne santé.
HEALTHCHECK CMD curl --fail http://localhost:5000/health || exit 1
On peut utiliser des variables d’environnement dans les Dockerfiles. La syntaxe est ${...}.
Exemple :
FROM busybox
ENV FOO=/bar
WORKDIR ${FOO} # WORKDIR /bar
ADD . $FOO # ADD . /bar
COPY \$FOO /quux # COPY $FOO /quux
Se référer au mode d’emploi pour la logique plus précise de fonctionnement des variables.
docker build [-t <tag:version>] [-f <chemin_du_dockerfile>] <contexte_de_construction>
Lors de la construction, Docker télécharge l’image de base. On constate plusieurs téléchargements en parallèle.
Il lance ensuite la séquence des instructions du Dockerfile.
Observez l’historique de construction de l’image avec docker image history <image>
Il lance ensuite la série d’instructions du Dockerfile et indique un hash pour chaque étape.
Docker construit les images comme une série de “couches” de fichiers successives.
On parle d'Union Filesystem car chaque couche (de fichiers) écrase la précédente.
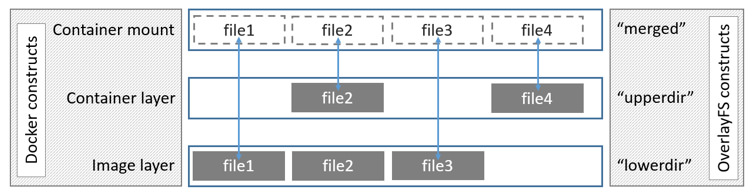
Chaque couche correspond à une instruction du Dockerfile.
docker image history <conteneur> permet d’afficher les layers, leur date de construction et taille respectives.
Ce principe est au coeur de l'immutabilité des images Docker.
Au lancement d’un container, le Docker Engine rajoute une nouvelle couche de filesystem “normal” read/write par dessus la pile des couches de l’image.
docker diff <container> permet d’observer les changements apportés au conteneur depuis le lancement.
Les images Docker ont souvent une taille de plusieurs centaines de mégaoctets voire parfois gigaoctets. docker image ls permet de voir la taille des images.
Or, on construit souvent plusieurs dizaines de versions d’une application par jour (souvent automatiquement sur les serveurs d’intégration continue).
Le principe de Docker est justement d’avoir des images légères car on va créer beaucoup de conteneurs (un par instance d’application/service).
De plus on télécharge souvent les images depuis un registry, ce qui consomme de la bande passante.
La principale bonne pratique dans la construction d’images est de limiter leur taille au maximum.
Choisir une image Linux de base minimale:
ubuntu complète pèse déjà presque une soixantaine de mégaoctets.busybox) est difficile à débugger et peu bloquer pour certaines tâches à cause de binaires ou de bibliothèques logicielles qui manquent (compilation par exemple).alpine qui est un bon compromis (6 mégaoctets seulement et un gestionnaire de paquets apk).python3 est fourni en version python:alpine (99 Mo), python:3-slim (179 Mo) et python:latest (918 Mo).Quand on tente de réduire la taille d’une image, on a recours à un tas de techniques. Avant, on utilisait deux Dockerfile différents : un pour la version prod, léger, et un pour la version dev, avec des outils en plus. Ce n’était pas idéal.
Par ailleurs, il existe une limite du nombre de couches maximum par image (42 layers). Souvent on enchaînait les commandes en une seule pour économiser des couches (souvent, les commandes RUN et ADD), en y perdant en lisibilité.
Maintenant on peut utiliser les multistage builds.
Avec les multi-stage builds, on peut utiliser plusieurs instructions FROM dans un Dockerfile. Chaque instruction FROM utilise une base différente.
On sélectionne ensuite les fichiers intéressants (des fichiers compilés par exemple) en les copiant d’un stage à un autre.
Exemple de Dockerfile utilisant un multi-stage build :
FROM golang:1.7.3 AS builder
WORKDIR /go/src/github.com/alexellis/href-counter/
RUN go get -d -v golang.org/x/net/html
COPY app.go .
RUN CGO_ENABLED=0 GOOS=linux go build -a -installsuffix cgo -o app .
FROM alpine:latest
RUN apk --no-cache add ca-certificates
WORKDIR /root/
COPY --from=builder /go/src/github.com/alexellis/href-counter/app .
CMD ["./app"]
Il n’est pas nécessaire de partir d’une image Linux vierge pour construire un conteneur.
On peut utiliser la directive FROM avec n’importe quelle image.
De nombreuses applications peuvent être configurées en étendant une image officielle
Exemple : une image Wordpress déjà adaptée à des besoins spécifiques.
L’intérêt ensuite est que l’image est disponible préconfigurée pour construire ou mettre à jour une infrastructure, ou lancer plusieurs instances (plusieurs containers) à partir de cette image.
C’est grâce à cette fonctionnalité que Docker peut être considéré comme un outil d'infrastructure as code.
On peut également prendre une sorte de snapshot du conteneur (de son système de fichiers, pas des processus en train de tourner) sous forme d’image avec docker commit <image> et docker push.
Généralement les images spécifiques produites par une entreprise n’ont pas vocation à finir dans un dépôt public.
On peut installer des registries privés.
On utilise alors docker login <adresse_repo> pour se logger au registry et le nom du registry dans les tags de l’image.
Exemples de registries :
git clone https://github.com/uptime-formation/microblog/
Ouvrez VSCode avec le dossier microblog en tapant code microblog ou bien en lançant VSCode avec code puis en cliquant sur Open Folder.
Dans VSCode, vous pouvez faire Terminal > New Terminal pour obtenir un terminal en bas de l’écran.
Déployer une application Flask manuellement à chaque fois est relativement pénible. Pour que les dépendances de deux projets Python ne se perturbent pas, il faut normalement utiliser un environnement virtuel virtualenv pour séparer ces deux apps.
Avec Docker, les projets sont déjà isolés dans des conteneurs. Nous allons donc construire une image de conteneur pour empaqueter l’application et la manipuler plus facilement. Assurez-vous que Docker est installé.
Pour connaître la liste des instructions des Dockerfiles et leur usage, se référer au manuel de référence sur les Dockerfiles.
Dans le dossier du projet ajoutez un fichier nommé Dockerfile et sauvegardez-le
Normalement, VSCode vous propose d’ajouter l’extension Docker. Il va nous faciliter la vie, installez-le. Une nouvelle icône apparaît dans la barre latérale de gauche, vous pouvez y voir les images téléchargées et les conteneurs existants. L’extension ajoute aussi des informations utiles aux instructions Dockerfile quand vous survolez un mot-clé avec la souris.
Ajoutez en haut du fichier : FROM ubuntu:latest Cette commande indique que notre image de base est la dernière version de la distribution Ubuntu.
Nous pouvons déjà contruire un conteneur à partir de ce modèle Ubuntu vide :
docker build -t microblog .
Une fois la construction terminée lancez le conteneur.
Le conteneur s’arrête immédiatement. En effet il ne contient aucune commande bloquante et nous n’avons précisé aucune commande au lancement. Pour pouvoir observer le conteneur convenablement il fautdrait faire tourner quelque chose à l’intérieur. Ajoutez à la fin du fichier la ligne :
CMD ["/bin/sleep", "3600"]
Cette ligne indique au conteneur d’attendre pendant 3600 secondes comme au TP précédent.
Reconstruisez l’image et relancez un conteneur
Affichez la liste des conteneurs en train de fonctionner
Nous allons maintenant rentrer dans le conteneur en ligne de commande pour observer. Utilisez la commande : docker exec -it <id_du_conteneur> /bin/bash
Vous êtes maintenant dans le conteneur avec une invite de commande. Utilisez quelques commandes Linux pour le visiter rapidement (ls, cd…).
Il s’agit d’un Linux standard, mais il n’est pas conçu pour être utilisé comme un système complet, juste pour une application isolée. Il faut maintenant ajouter notre application Flask à l’intérieur. Dans le Dockerfile supprimez la ligne CMD, puis ajoutez :
RUN apt-get update -y
RUN apt-get install -y python3-pip
Reconstruisez votre image. Si tout se passe bien, poursuivez.
Pour installer les dépendances python et configurer la variable d’environnement Flask ajoutez:
COPY ./requirements.txt /requirements.txt
RUN pip3 install -r requirements.txt
ENV FLASK_APP microblog.py
Reconstruisez votre image. Si tout se passe bien, poursuivez.
Ensuite, copions le code de l’application à l’intérieur du conteneur. Pour cela ajoutez les lignes :
COPY ./ /microblog
WORKDIR /microblog
Cette première ligne indique de copier tout le contenu du dossier courant sur l’hôte dans un dossier /microblog à l’intérieur du conteneur.
Nous n’avons pas copié les requirements en même temps pour pouvoir tirer partie des fonctionnalités de cache de Docker, et ne pas avoir à retélécharger les dépendances de l’application à chaque fois que l’on modifie le contenu de l’app.
Puis, dans la 2e ligne, le dossier courant dans le conteneur est déplacé à /.
Reconstruisez votre image. Observons que le build recommence à partir de l’instruction modifiée. Les layers précédents avaient été mis en cache par le Docker Engine.
Si tout se passe bien, poursuivez.
Enfin, ajoutons la section de démarrage à la fin du Dockerfile, c’est un script appelé boot.sh :
CMD ["./boot.sh"]
Reconstruisez l’image et lancez un conteneur basé sur l’image en ouvrant le port 5000 avec la commande : docker run -p 5000:5000 microblog
Naviguez dans le navigateur à l’adresse localhost:5000 pour admirer le prototype microblog.
Lancez un deuxième container cette fois avec : docker run -d -p 5001:5000 microblog
Une deuxième instance de l’app est maintenant en fonctionnement et accessible à l’adresse localhost:5001
docker login, docker tag et docker push, poussez l’image microblog sur le Docker Hub. Créez un compte sur le Docker Hub le cas échéant.python:3-alpine et en remplaçant les instructions nécessaires (pas besoin d’installer python3-pip car ce programme est désormais inclus dans l’image de base), repackagez l’app microblog en une image taggée microblog:slim ou microblog:light. Comparez la taille entre les deux images ainsi construites.Le serveur de développement Flask est bien pratique pour debugger en situation de développement, mais n’est pas adapté à la production. Nous pourrions créer deux images pour les deux situations mais ce serait aller contre l’impératif DevOps de rapprochement du dev et de la prod.
Pour démarrer l’application, nous avons fait appel à un script de boot boot.sh avec à l’intérieur :
#!/bin/bash
# ...
set -e
if [ "$APP_ENVIRONMENT" = 'DEV' ]; then
echo "Running Development Server"
exec flask run -h 0.0.0.0
else
echo "Running Production Server"
exec gunicorn -b :5000 --access-logfile - --error-logfile - app_name:app
fi
Déclarez maintenant dans le Dockerfile la variable d’environnement APP_ENVIRONMENT avec comme valeur par défaut PROD.
Construisez l’image avec build.
Puis, grâce aux bons arguments allant avec docker run, lancez une instance de l’app en configuration PROD et une instance en environnement DEV (joignables sur deux ports différents).
Avec docker ps ou en lisant les logs, vérifiez qu’il existe bien une différence dans le programme lancé.
EXPOSE 5000 pour indiquer à Docker que cette app est censée être accédée via son port 5000.-p port_de_l-hote:port_du_container reste nécessaire, l’instruction EXPOSE n’est là qu’à titre de documentation de l’image.HEALTHCHECK permet de vérifier si l’app contenue dans un conteneur est en bonne santé.
Dockerfile dont le contenu est le suivant :FROM python:alpine
RUN apk add curl
RUN pip install flask==0.10.1
ADD /app.py /app/app.py
WORKDIR /app
HEALTHCHECK CMD curl --fail http://localhost:5000/health || exit 1
CMD python app.py
app.py avec ce contenu :from flask import Flask
healthy = True
app = Flask(__name__)
@app.route('/health')
def health():
global healthy
if healthy:
return 'OK', 200
else:
return 'NOT OK', 500
@app.route('/kill')
def kill():
global healthy
healthy = False
return 'You have killed your app.', 200
if __name__ == "__main__":
app.run(host="0.0.0.0")
Observez bien le code Python et la ligne HEALTHCHECK du Dockerfile puis lancez l’app. A l’aide de docker ps, relevez où Docker indique la santé de votre app.
Visitez l’URL /kill de votre app dans un navigateur. Refaites docker ps. Que s’est-il passé ?
(Facultatif) Rajoutez une instruction HEALTHCHECK au Dockerfile de notre app microblog.
Une image est composée de plusieurs layers empilés entre eux par le Docker Engine et de métadonnées.
Affichez la liste des images présentes dans votre Docker Engine.
Inspectez la dernière image que vous venez de créez (docker image --help pour trouver la commande)
Observez l’historique de construction de l’image avec docker image history <image>
Visitons en root (sudo su) le dossier /var/lib/docker/ sur l’hôte. En particulier, image/overlay2/layerdb/sha256/ :
Vous pouvez aussi utiliser la commande docker save votre_image -o image.tar, et utiliser tar -C image_decompressee/ -xvf image.tar pour décompresser une image Docker puis explorer les différents layers de l’image.
Pour explorer la hiérarchie des images vous pouvez installer https://github.com/wagoodman/dive
Créons un nouveau Dockerfile qui permet de faire dire des choses à une vache grâce à la commande cowsay.
Le but est de faire fonctionner notre programme dans un conteneur à partir de commandes de type :
docker run --rm cowsay Coucou !
docker run --rm cowsay -f stegosaurus Yo!
docker run --rm cowsay -f elephant-in-snake Un éléphant dans un boa.
Doit-on utiliser la commande ENTRYPOINT ou la commande CMD ? Se référer au manuel de référence sur les Dockerfiles si besoin.
Pour information, cowsay s’installe dans /usr/games/cowsay.
La liste des options (incontournables) de cowsay se trouve ici : https://debian-facile.org/doc:jeux:cowsay
ENTRYPOINT et la gestion des entrées-sorties des programmes dans les Dockerfiles peut être un peu capricieuse et il faut parfois avoir de bonnes notions de Bash et de Linux pour comprendre (et bien lire la documentation Docker).--rm pour les supprimer dès qu’ils s’arrêtent.Transformez le Dockerfile de l’app dnmonster située à l’adresse suivante pour réaliser un multi-stage build afin d’obtenir l’image finale la plus légère possible :
https://github.com/amouat/dnmonster/
La documentation pour les multi-stage builds est à cette adresse : https://docs.docker.com/develop/develop-images/multistage-build/
Conséquences :
Solutions :
L’instruction EXPOSE dans le Dockerfile informe Docker que le conteneur écoute sur les ports réseau au lancement. L’instruction EXPOSE ne publie pas les ports. C’est une sorte de documentation entre la personne qui construit les images et la personne qui lance le conteneur à propos des ports que l’on souhaite publier.
Par défaut les conteneurs n’ouvrent donc pas de port même s’ils sont déclarés avec EXPOSE dans le Dockerfile.
Pour publier un port au lancement d’un conteneur, c’est l’option -p <port_host>:<port_guest> de docker run.
Instruction port: d’un compose file.
Un réseau bridge est une façon de créer un pont entre deux carte réseaux pour construire un réseau à partir de deux.
Par défaut les réseaux docker fonctionne en bridge (le réseau de chaque conteneur est bridgé à un réseau virtuel docker)
par défaut les adresses sont en 172.0.0.0/8, typiquement chaque hôte définit le bloc d’IP 172.17.0.0/16 configuré avec DHCP.
Serveur DNS et DHCP intégré dans le “user-defined network” (c’est une solution IPAM)
Donne un nom de domaine automatique à chaque conteneur.
Mais ne pas avoir peur d’aller voir comment on perçoit le réseau de l’intérieur. Nécessaire pour bien contrôler le réseau.
ingress : un loadbalancer automatiquement connecté aux nœuds d’un Swarm. Voir la doc sur les réseaux overlay.
Aujourd’hui il faut utiliser un réseau dédié créé par l’utilisateur (“user-defined bridge network”)
--network de docker runnetworks: dans un docker composerOn peut aussi créer un lien entre des conteneurs
--link de docker runlink: dans un docker composerIl existe :
volumedocker volume lsdocker volume inspectdocker volume prunedocker volume createdocker volume rmLorsqu’un répertoire hôte spécifique est utilisé dans un volume (la syntaxe -v HOST_DIR:CONTAINER_DIR), elle est souvent appelée bind mounting (“montage lié”).
C’est quelque peu trompeur, car tous les volumes sont techniquement “bind mounted”. La particularité, c’est que le point de montage sur l’hôte est explicite plutôt que caché dans un répertoire appartenant à Docker.
Exemple :
docker run -it -v /tmp/data:/data ubuntu /bin/bash
cd /data/
touch testfile
exit
ls /tmp/data/
VOLUME dans un DockerfileL’instruction VOLUME dans un Dockerfile permet de désigner les volumes qui devront être créés lors du lancement du conteneur. On précise ensuite avec l’option -v de docker run à quoi connecter ces volumes. Si on ne le précise pas, Docker crée quand même un volume Docker au nom généré aléatoirement, un volume “caché”.
Pour partager des données on peut monter le même volume dans plusieurs conteneurs.
Pour lancer un conteneur avec les volumes d’un autre conteneur déjà montés on peut utiliser --volumes-from <container>
On peut aussi créer le volume à l’avance et l’attacher après coup à un conteneur.
Par défaut le driver de volume est local c’est-à-dire qu’un dossier est créé sur le disque de l’hôte.
docker volume create --driver local \
--opt type=btrfs \
--opt device=/dev/sda2 \
monVolume
On peut utiliser d’autres systèmes de stockage en installant de nouveau plugins de driver de volume. Par exemple, le plugin vieux/sshfs permet de piloter un volume distant via SSH.
Exemples:
docker volume create -d vieux/sshfs -o sshcmd=<sshcmd> -o allow_other sshvolume
docker run -p 8080:8080 -v sshvolume:/path/to/folder --name test someimage
Ou via docker-compose :
volumes:
sshfsdata:
driver: vieux/sshfs:latest
driver_opts:
sshcmd: "username@server:/location/on/the/server"
allow_other: ""
FROM debian
RUN groupadd -r graphite && useradd -r -g graphite graphite
RUN mkdir -p /data/graphite && chown -R graphite:graphite /data/graphite
VOLUME /data/graphite
USER graphite
CMD ["echo", "Data container for graphite"]
--volume-fromprune car il reste un conteneur qui y est liéSi vous aviez déjà créé le conteneur Portainer, vous pouvez le relancer en faisant docker start portainer, sinon créez-le comme suit :
docker volume create portainer_data
docker run --detach --name portainer \
-p 9000:9000 \
-v portainer_data:/data \
-v /var/run/docker.sock:/var/run/docker.sock \
portainer/portainer-ce
Pour expérimenter avec le réseau, nous allons lancer une petite application nodejs d’exemple (moby-counter) qui fonctionne avec une file (queue) redis (comme une base de données mais pour stocker des paires clé/valeur simples).
Récupérons les images depuis Docker Hub:
docker image pull redis:alpine
docker image pull russmckendrick/moby-counter
Lancez la commande ip a | tee /tmp/interfaces_avant.txt pour lister vos interfaces réseau et les écrire dans le fichier
Pour connecter les deux applications créons un réseau manuellement:
docker network create moby-networkDocker implémente ces réseaux virtuels en créant des interfaces. Lancez la commande ip a | tee /tmp/interfaces_apres.txt et comparez (diff /tmp/interfaces_avant.txt /tmp/interfaces_apres.txt). Qu’est-ce qui a changé ?
Maintenant, lançons les deux applications en utilisant notre réseau :
docker run -d --name redis --network <réseau> redis:alpine
docker run -d --name moby-counter --network <réseau> -p 80:80 russmckendrick/moby-counter
Visitez la page de notre application. Qu’en pensez vous ? Moby est le nom de la mascotte Docker 🐳 😊. Faites un motif reconnaissable en cliquant.
Comment notre application se connecte-t-elle au conteneur redis ? Elle utilise ces instructions JS dans son fichier server.js:
var port = opts.redis_port || process.env.USE_REDIS_PORT || 6379;
var host = opts.redis_host || process.env.USE_REDIS_HOST || "redis";
En résumé par défaut, notre application se connecte sur l’hôte redis avec le port 6379
Explorons un peu notre réseau Docker.
docker exec) la commande ping -c 3 redis à l’intérieur de notre conteneur applicatif (moby-counter donc). Quelle est l’adresse IP affichée ?docker exec moby-counter ping -c3 redis
De même, affichez le contenu des fichiers /etc/hosts du conteneur (c’est la commande cat couplée avec docker exec). Nous constatons que Docker a automatiquement configuré l’IP externe du conteneur dans lequel on est avec l’identifiant du conteneur. De même, affichez /etc/resolv.conf : le résolveur DNS a été configuré par Docker. C’est comme ça que le conteneur connaît l’adresse IP de redis. Pour s’en assurer, interrogeons le serveur DNS de notre réseau moby-network en lançant la commande nslookup redis 127.0.0.11 toujours grâce à docker exec :
docker exec moby-counter nslookup redis 127.0.0.11
Créez un deuxième réseau moby-network2
Créez une deuxième instance de l’application dans ce réseau : docker run -d --name moby-counter2 --network moby-network2 -p 9090:80 russmckendrick/moby-counter
Lorsque vous pingez redis depuis cette nouvelle instance moby-counter2, qu’obtenez-vous ? Pourquoi ?
Vous ne pouvez pas avoir deux conteneurs avec les mêmes noms, comme nous l’avons déjà découvert.
Par contre, notre deuxième réseau fonctionne complètement isolé de notre premier réseau, ce qui signifie que nous pouvons toujours utiliser le nom de domaine redis. Pour ce faire, nous devons spécifier l’option --network-alias :
Créons un deuxième redis avec le même domaine: docker run -d --name redis2 --network moby-network2 --network-alias redis redis:alpine
Lorsque vous pingez redis depuis cette nouvelle instance de l’application, quelle IP obtenez-vous ?
Récupérez comme auparavant l’adresse IP du nameserver local pour moby-counter2.
Puis lancez nslookup redis <nameserver_ip> dans le conteneur moby-counter2 pour tester la résolution de DNS.
Vous pouvez retrouver la configuration du réseau et les conteneurs qui lui sont reliés avec docker network inspect moby-network2.
Notez la section IPAM (IP Address Management).
Arrêtons nos conteneurs : docker stop moby-counter2 redis2.
Pour faire rapidement le ménage des conteneurs arrêtés lancez docker container prune.
De même docker network prune permet de faire le ménage des réseaux qui ne sont plus utilisés par aucun conteneur.
Si vous aviez déjà créé le conteneur Portainer, vous pouvez le relancer en faisant docker start portainer, sinon créez-le comme suit :
docker volume create portainer_data
docker run --detach --name portainer \
-p 9000:9000 \
-v portainer_data:/data \
-v /var/run/docker.sock:/var/run/docker.sock \
portainer/portainer-ce
/tmp/data de l’hôte au dossier /data sur le conteneur :docker run -it -v /tmp/data:/data ubuntu /bin/bash
cd /data/
touch testfile
exitexit
ls /tmp/data/
Le fichier testfile a été crée par le conteneur au dossier que l’on avait connecté grâce à -v /tmp/data:/data
moby-counter, Redis et les volumesPour ne pas interférer avec la deuxième partie du TP :
docker stop ou avec Portainer.docker container prunedocker volume prune pour faire le ménage de volume éventuellement créés dans les TPs précédentdocker network prune pour nettoyer les réseaux inutilisésPassons à l’exploration des volumes:
moby-network et les conteneurs redis et moby-counter à l’intérieur :docker network create moby-network
docker run -d --name redis --network moby-network redis
docker run -d --name moby-counter --network moby-network -p 8000:80 russmckendrick/moby-counter
supprimez le conteneur redis : docker stop redis puis docker rm redis
Visitez votre application dans le navigateur. Elle est maintenant déconnectée de son backend.
Avons-nous vraiment perdu les données de notre conteneur précédent ? Non ! Le Dockerfile pour l’image officielle Redis ressemble à ça :
FROM alpine:3.5
RUN addgroup -S redis && adduser -S -G redis redis
RUN apk add --no-cache 'su-exec>=0.2'
ENV REDIS_VERSION 3.0.7
ENV REDIS_DOWNLOAD_URL http://download.redis.io/releases/redis-3.0.7.tar.gz
ENV REDIS_DOWNLOAD_SHA e56b4b7e033ae8dbf311f9191cf6fdf3ae974d1c
RUN set -x \
&& apk add --no-cache --virtual .build-deps \
gcc \
linux-headers \
make \
musl-dev \
tar \
&& wget -O redis.tar.gz "$REDIS_DOWNLOAD_URL" \
&& echo "$REDIS_DOWNLOAD_SHA *redis.tar.gz" | sha1sum -c - \
&& mkdir -p /usr/src/redis \
&& tar -xzf redis.tar.gz -C /usr/src/redis --strip-components=1 \
&& rm redis.tar.gz \
&& make -C /usr/src/redis \
&& make -C /usr/src/redis install \
&& rm -r /usr/src/redis \
&& apk del .build-deps
RUN mkdir /data && chown redis:redis /data
VOLUME /data
WORKDIR /data
COPY docker-entrypoint.sh /usr/local/bin/
RUN ln -s usr/local/bin/docker-entrypoint.sh /entrypoint.sh # backwards compat
ENTRYPOINT ["docker-entrypoint.sh"]
EXPOSE 6379
CMD [ "redis-server" ]Notez que, vers la fin du fichier, il y a une instruction VOLUME ; cela signifie que lorque notre conteneur a été lancé, un volume “caché” a effectivement été créé par Docker.
Beaucoup de conteneurs Docker sont des applications stateful, c’est-à-dire qui stockent des données. Automatiquement ces conteneurs créent des volument anonymes en arrière plan qu’il faut ensuite supprimer manuellement (avec rm ou prune).
Inspectez la liste des volumes (par exemple avec Portainer) pour retrouver l’identifiant du volume caché. Normalement il devrait y avoir un volume portainer_data (si vous utilisez Portainer) et un volume anonyme avec un hash.
Créez un nouveau conteneur redis en le rattachant au volume redis “caché” que vous avez retrouvé (en copiant l’id du volume anonyme) :
docker container run -d --name redis -v <volume_id>:/data --network moby-network redis:alpine
Visitez la page de l’application. Normalement un motif de logos moby d’une précédente session devrait s’afficher (après un délai pouvant aller jusqu’à plusieurs minutes)
Affichez le contenu du volume avec la commande : docker exec redis ls -lha /data
Finalement, nous allons recréer un conteneur avec un volume qui n’est pas anonyme.
En effet, la bonne façon de créer des volumes consiste à les créer manuellement (volumes nommés) : docker volume create redis_data.
redis puis créez un nouveau conteneur attaché à ce volume nommé : docker container run -d --name redis -v redis_data:/data --network moby-network redis:alpineLorsqu’un répertoire hôte spécifique est utilisé dans un volume (la syntaxe -v HOST_DIR:CONTAINER_DIR), elle est souvent appelée bind mounting.
C’est quelque peu trompeur, car tous les volumes sont techniquement “bind mounted”. La différence, c’est que le point de montage est explicite plutôt que caché dans un répertoire géré par Docker.
docker volume inspect redis_data.Pour nettoyer tout ce travail, arrêtez d’abord les différents conteneurs redis et moby-counter.
Lancez la fonction prune pour les conteneurs d’abord, puis pour les réseaux, et enfin pour les volumes.
Comme les réseaux et volumes n’étaient plus attachés à des conteneurs en fonctionnement, ils ont été supprimés.
Généralement, il faut faire beaucoup plus attention au prune de volumes (données à perdre) qu’au prune de conteneurs (rien à perdre car immutable et en général dans le registry).
VOLUME avec microblogRendez-vous dans votre répertoire racine en tapant cd.
Après être entré·e dans le repo microblog grâce à cd microblog, récupérez une version déjà dockerisée de l’app en chargeant le contenu de la branche Git tp2-dockerfile en faisant git checkout tp2-dockerfile -- Dockerfile.
Si vous n’aviez pas encore le repo microblog :
git clone https://github.com/uptime-formation/microblog/
cd microblog
git checkout tp2-dockerfile
Dockerfile de l’application microblog.Un volume Docker apparaît comme un dossier à l’intérieur du conteneur.
Nous allons faire apparaître le volume Docker comme un dossier à l’emplacement /data sur le conteneur.
Dockerfile une variable d’environnement DATABASE_URL ainsi (cette variable est lue par le programme Python) :ENV DATABASE_URL=sqlite:////data/app.db
Dockerfile une instruction VOLUME pour stocker la base de données SQLite de l’application.microblog_db, et lancez un conteneur l’utilisant, créez un compte et écrivez un message.microblog utilisant le même volume nommé.Vous possédez tous les ingrédients pour packager l’app de votre choix désormais ! Récupérez une image de base, basez-vous sur un Dockerfile existant s’il vous inspire, et lancez-vous !
Nous avons pu constater que lancer plusieurs conteneurs liés avec leur mapping réseau et les volumes liés implique des commandes assez lourdes. Cela devient ingérable si l’on a beaucoup d’applications microservice avec des réseaux et des volumes spécifiques.
Pour faciliter tout cela et dans l’optique d'Infrastructure as Code, Docker introduit un outil nommé docker-compose qui permet de décrire de applications multiconteneurs grâce à des fichiers YAML.
Pour bien comprendre qu’il ne s’agit que de convertir des options de commande Docker en YAML, un site vous permet de convertir une commande docker run en fichier Docker Compose : https://www.composerize.com/
- marché:
lieu: Marché de la Défense
jour: jeudi
horaire:
unité: "heure"
min: 12
max: 20
fruits:
- nom: pomme
couleur: "verte"
pesticide: avec
- nom: poires
couleur: jaune
pesticide: sans
légumes:
- courgettes
- salade
- potiron
Alignement ! (2 espaces !!)
ALIGNEMENT !! (comme en python)
ALIGNEMENT !!! (le défaut du YAML, pas de correcteur syntaxique automatique, c’est bête mais vous y perdrez forcément quelques heures !
des listes (tirets)
des paires clé: valeur
Un peu comme du JSON, avec cette grosse différence que le JSON se fiche de l’alignement et met des accolades et des points-virgules
les extensions Docker et YAML dans VSCode vous aident à repérer des erreurs
version: 3
services:
postgres:
image: postgres:10
environment:
POSTGRES_USER: rails_user
POSTGRES_PASSWORD: rails_password
POSTGRES_DB: rails_db
networks:
- back_end
redis:
image: redis:3.2-alpine
networks:
- back_end
rails:
build: .
depends_on:
- postgres
- redis
environment:
DATABASE_URL: "postgres://rails_user:rails_password@postgres:5432/rails_db"
REDIS_HOST: "redis:6379"
networks:
- front_end
- back_end
volumes:
- .:/app
nginx:
image: nginx:latest
networks:
- front_end
ports:
- 3000:80
volumes:
- ./nginx.conf:/etc/nginx/conf.d/default.conf:ro
networks:
front_end:
back_end:
Un deuxième exemple :
version: "3.3"
services:
mysql:
container_name: mysqlpourwordpress
environment:
- MYSQL_ROOT_PASSWORD=motdepasseroot
- MYSQL_DATABASE=wordpress
- MYSQL_USER=wordpress
- MYSQL_PASSWORD=monwordpress
networks:
- wordpress
image: "mysql:5.7"
wordpress:
depends_on:
- mysql
container_name: wordpressavecmysql
environment:
- "WORDPRESS_DB_HOST=mysqlpourwordpress:3306"
- WORDPRESS_DB_PASSWORD=monwordpress
- WORDPRESS_DB_USER=wordpress
networks:
- wordpress
ports:
- "80:80"
image: wordpress
volumes:
- wordpress_config:/var/www/html/
networks:
wordpress:
volumes:
wordpress_config:
Les commandes suivantes sont couramment utilisées lorsque vous travaillez avec Compose. La plupart se passent d’explications et ont des équivalents Docker directs, mais il vaut la peine d’en être conscient·e :
up démarre tous les conteneurs définis dans le fichier compose et agrège la sortie des logs. Normalement, vous voudrez utiliser l’argument -d pour exécuter Compose en arrière-plan.
build reconstruit toutes les images créées à partir de Dockerfiles. La commande up ne construira pas une image à moins qu’elle n’existe pas, donc utilisez cette commande à chaque fois que vous avez besoin de mettre à jour une image (quand vous avez édité un Dockerfile). On peut aussi faire docker-compose up --build
ps fournit des informations sur le statut des conteneurs gérés par Compose.
run fait tourner un conteneur pour exécuter une commande unique. Cela aura aussi pour effet de faire tourner tout conteneur décrit dans depends_on, à moins que l’argument --no-deps ne soit donné.
logs affiche les logs. De façon générale la sortie des logs est colorée et agrégée pour les conteneurs gérés par Compose.
stop arrête les conteneurs sans les enlever.
rm enlève les contenants à l’arrêt. N’oubliez pas d’utiliser l’argument -v pour supprimer tous les volumes gérés par Docker.
down détruit tous les conteneurs définis dans le fichier Compose, ainsi que les réseaux
docker-compose.Certaines applications microservice peuvent avoir potentiellement des dizaines de petits conteneurs spécialisés. Le service devient alors difficile à lire dans le compose file.
Il est possible de visualiser l’architecture d’un fichier Docker Compose en utilisant docker-compose-viz
Cet outil peut être utilisé dans un cadre d’intégration continue pour produire automatiquement la documentation pour une image en fonction du code.
sudo apt install docker-compose.
identidock : une application Flask qui se connecte à redisidentidock et chargez-le avec la fonction Add folder to workspace)app, ajoutez une petite application python en créant ce fichier identidock.py :from flask import Flask, Response, request
import requests
import hashlib
import redis
app = Flask(__name__)
cache = redis.StrictRedis(host='redis', port=6379, db=0)
salt = "UNIQUE_SALT"
default_name = 'Joe Bloggs'
@app.route('/', methods=['GET', 'POST'])
def mainpage():
name = default_name
if request.method == 'POST':
name = request.form['name']
salted_name = salt + name
name_hash = hashlib.sha256(salted_name.encode()).hexdigest()
header = '<html><head><title>Identidock</title></head><body>'
body = '''<form method="POST">
Hello <input type="text" name="name" value="{0}">
<input type="submit" value="submit">
</form>
<p>You look like a:
<img src="/monster/{1}"/>
'''.format(name, name_hash)
footer = '</body></html>'
return header + body + footer
@app.route('/monster/<name>')
def get_identicon(name):
image = cache.get(name)
if image is None:
print ("Cache miss", flush=True)
r = requests.get('http://dnmonster:8080/monster/' + name + '?size=80')
image = r.content
cache.set(name, image)
return Response(image, mimetype='image/png')
if __name__ == '__main__':
app.run(debug=True, host='0.0.0.0', port=9090)
uWSGI est un serveur python de production très adapté pour servir notre serveur intégré Flask, nous allons l’utiliser.
Dockerisons maintenant cette nouvelle application avec le Dockerfile suivant :
FROM python:3.7
RUN groupadd -r uwsgi && useradd -r -g uwsgi uwsgi
RUN pip install Flask uWSGI requests redis
WORKDIR /app
COPY app/identidock.py /app
EXPOSE 9090 9191
USER uwsgi
CMD ["uwsgi", "--http", "0.0.0.0:9090", "--wsgi-file", "/app/identidock.py", \
"--callable", "app", "--stats", "0.0.0.0:9191"]
Observons le code du Dockerfile ensemble s’il n’est pas clair pour vous. Juste avant de lancer l’application, nous avons changé d’utilisateur avec l’instruction USER, pourquoi ?.
Construire l’application, pour l’instant avec docker build, la lancer et vérifier avec docker exec, whoami et id l’utilisateur avec lequel tourne le conteneur.
identidock (à côté du Dockerfile), créez un fichier de déclaration de notre application appelé docker-compose.yml avec à l’intérieur :version: "3.7"
services:
identidock:
build: .
ports:
- "9090:9090"
Plusieurs remarques :
services déclare le conteneur de notre applicationbuild: . indique que l’image d’origine de notre conteneur est le résultat de la construction d’une image à partir du répertoire courant (équivaut à docker build -t identidock .)Lancez le service (pour le moment mono-conteneur) avec docker-compose up (cette commande sous-entend docker-compose build)
Visitez la page web de l’app.
Ajoutons maintenant un deuxième conteneur. Nous allons tirer parti d’une image déjà créée qui permet de récupérer une “identicon”. Ajoutez à la suite du fichier Compose (attention aux indentations !) :
dnmonster:
image: amouat/dnmonster:1.0
Le docker-compose.yml doit pour l’instant ressembler à ça :
version: "3.7"
services:
identidock:
build: .
ports:
- "9090:9090"
dnmonster:
image: amouat/dnmonster:1.0
Enfin, nous déclarons aussi un réseau appelé identinet pour y mettre les deux conteneurs de notre application.
networks:
identinet:
driver: bridge
identidock et dnmonster sur le même réseau en ajoutant deux fois ce bout de code où c’est nécessaire (attention aux indentations !) :networks:
- identinet
redis (attention aux indentations !). Cette base de données sert à mettre en cache les images et à ne pas les recalculer à chaque fois.redis:
image: redis
networks:
- identinet
docker-compose.yml final :
version: "3.7"
services:
identidock:
build: .
ports:
- "9090:9090"
networks:
- identinet
dnmonster:
image: amouat/dnmonster:1.0
networks:
- identinet
redis:
image: redis
networks:
- identinet
networks:
identinet:
driver: bridge
Lancez l’application et vérifiez que le cache fonctionne en chercheant les cache miss dans les logs de l’application.
N’hésitez pas à passer du temps à explorer les options et commandes de docker-compose, ainsi que la documentation officielle du langage des Compose files. Cette documentation indique aussi les différences entre la version 2 et la version 3 des fichiers Docker Compose.
Récupérez (et adaptez si besoin) à partir d’Internet un fichier docker-compose.yml permettant de lancer un pad CodiMD avec sa base de données. Je vous conseille de toujours chercher dans la documentation officielle ou le repository officiel (souvent sur Github) en premier. Attention, CodiMD avant s’appelait HackMD.
Vérifiez que le pad est bien accessible sur le port donné.
L’utilité d’Elasticsearch est que, grâce à une configuration très simple de son module Filebeat, nous allons pouvoir centraliser les logs de tous nos conteneurs Docker. Pour ce faire, il suffit d’abord de télécharger une configuration de Filebeat prévue à cet effet :
curl -L -O https://raw.githubusercontent.com/elastic/beats/7.10/deploy/docker/filebeat.docker.yml
Renommons cette configuration et rectifions qui possède ce fichier pour satisfaire une contrainte de sécurité de Filebeat :
mv filebeat.docker.yml filebeat.yml
sudo chown root filebeat.yml
Enfin, créons un fichier docker-compose.yml pour lancer une stack Elasticsearch :
version: "3"
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.5.0
environment:
- discovery.type=single-node
- xpack.security.enabled=false
networks:
- logging-network
filebeat:
image: docker.elastic.co/beats/filebeat:7.5.0
user: root
depends_on:
- elasticsearch
volumes:
- ./filebeat.yml:/usr/share/filebeat/filebeat.yml:ro
- /var/lib/docker/containers:/var/lib/docker/containers:ro
- /var/run/docker.sock:/var/run/docker.sock:ro
networks:
- logging-network
environment:
- -strict.perms=false
kibana:
image: docker.elastic.co/kibana/kibana:7.5.0
depends_on:
- elasticsearch
ports:
- 5601:5601
networks:
- logging-network
networks:
logging-network:
driver: bridge
Il suffit ensuite de se rendre sur Kibana (port 5601) et de configurer l’index en tapant * dans le champ indiqué, de valider et de sélectionner le champ @timestamp, puis de valider. L’index nécessaire à Kibana est créé, vous pouvez vous rendre dans la partie Discover à gauche (l’icône boussole 🧭) pour lire vos logs.
Vous pouvez désormais faire l’exercice 1 du TP7 pour configurer un serveur web qui permet d’accéder à vos services via des domaines.
Un des intérêts principaux de Docker et des conteneurs en général est de :
A partir d’une certaine échelle, il n’est plus question de gérer les serveurs et leurs conteneurs à la main.
Les nœuds d’un cluster sont les machines (serveurs physiques, machines virtuelles, etc.) qui font tourner vos applications (composées de conteneurs).
L’orchestration consiste à automatiser la création et la répartition des conteneurs à travers un cluster de serveurs. Cela peut permettre de :
Swarm est l'outil de clustering et d’orchestration natif de Docker (développé par Docker Inc.).
Il s’intègre très bien avec les autres commandes docker (on a même pas l’impression de faire du clustering).
Il permet de gérer de très grosses productions Docker.
Swarm utilise l’API standard du Docker Engine (sur le port 2376) et sa propre API de management Swarm (sur le port 2377).
Il a perdu un peu en popularité face à Kubernetes mais c’est très relatif (voir comparaison plus loin).
 ]
]
L’algorithme Raft : http://thesecretlivesofdata.com/raft/
Pas d'intelligent balancing dans Swarm
les services : la distribution d’un seul conteneur en plusieurs exemplaires
les stacks : la distribution (en plusieurs exemplaires) d’un ensemble de conteneurs (app multiconteneurs) décrits dans un fichier Docker Compose
version: "3"
services:
web:
image: username/repo
deploy:
replicas: 5
resources:
limits:
cpus: "0.1"
memory: 50M
restart_policy:
condition: on-failure
ports:
- "4000:80"
networks:
- webnet
networks:
webnet:
deploy est lié à l’usage de Swarm
update_config : pour pouvoir rollback si l’update failplacement : pouvoir choisir le nœud sur lequel sera déployé le servicereplicas : nombre d’exemplaires du conteneurresources : contraintes d’utilisation de CPU ou de RAM sur le nœudswarm init : Activer Swarm et devenir manager d’un cluster d’un seul nœud
swarm join : Rejoindre un cluster Swarm en tant que nœud manager ou worker
service create : Créer un service (= un conteneur en plusieurs exemplaires)
service inspect : Infos sur un service
service ls : Liste des services
service rm : Supprimer un service
service scale : Modifier le nombre de conteneurs qui fournissent un service
service ps : Liste et état des conteneurs qui fournissent un service
service update : Modifier la définition d’un service
docker stack deploy : Déploie une stack (= fichier Docker compose) ou update une stack existante
docker stack ls : Liste les stacks
docker stack ps : Liste l’état du déploiement d’une stack
docker stack rm : Supprimer une ou des stacks
docker stack services : Liste les services qui composent une stack
docker node inspect : Informations détaillées sur un nœud
docker node ls : Liste les nœuds
docker node ps : Liste les tâches en cours sur un nœud
docker node promote : Transforme un nœud worker en manager
docker node demote : Transforme un nœud manager en worker
Un load balancer : une sorte d'“aiguillage” de trafic réseau, typiquement HTTP(S) ou TCP.
Un aiguillage intelligent qui se renseigne sur plusieurs critères avant de choisir la direction.
Cas d’usage :
Haute disponibilité : on veut que notre service soit toujours disponible, même en cas de panne (partielle) ou de maintenance.
Donc on va dupliquer chaque partie de notre service et mettre les différentes instances derrière un load balancer.
Le load balancer va vérifier pour chaque backend s’il est disponible (healthcheck) avant de rediriger le trafic.
Répartition géographique : en fonction de la provenance des requêtes on va rediriger vers un datacenter adapté (+ ou - proche)
Loadbalancer intégré : Ingress
Permet de router automatiquement le trafic d’un service vers les nœuds qui l’hébergent et sont disponibles.
Pour héberger une production il suffit de rajouter un loadbalancer externe qui pointe vers un certain nombre de nœuds du cluster et le trafic sera routé automatiquement à partir de l’un des nœuds.
echo "This is a secret" | docker secret create my_secret_data
docker service create --name monservice --secret my_secret_data redis:alpine
=> monte le contenu secret dans /var/run/my_secret_data
Concrètement, docker-machine permet de créer automatiquement des machines avec le Docker Engine et ssh configuré et de gérer les certificats TLS pour se connecter à l’API Docker des différents serveurs.
Il permet également de changer le contexte de la ligne de commande Docker pour basculer sur l’un ou l’autre serveur avec les variables d’environnement adéquates.
Il permet également de se connecter à une machine en ssh en une simple commande.
Exemple :
docker-machine create --driver digitalocean \
--digitalocean-ssh-key-fingerprint 41:d9:ad:ba:e0:32:73:58:4f:09:28:15:f2:1d:ae:5c \
--digitalocean-access-token "a94008870c9745febbb2bb84b01d16b6bf837b4e0ce9b516dbcaf4e7d5ff2d6" \
hote-digitalocean
Pour basculer eval $(docker env hote-digitalocean);
docker run -d nginx:latest créé ensuite un conteneur sur le droplet digitalocean précédemment créé.
docker ps -a affiche le conteneur en train de tourner à distance.
wget $(docker-machine ip hote-digitalocean) va récupérer la page nginx.
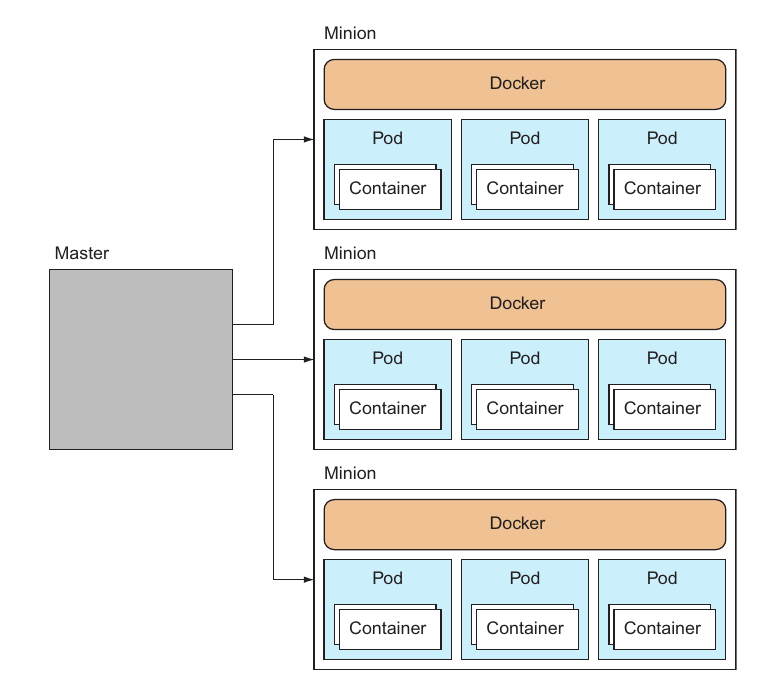
Les pods Kubernetes servent à grouper des conteneurs en unités d’application (microservices ou non) fortement couplées (un peu comme les stacks Swarm)
Les services sont des groupes de pods exposés à l’extérieur
Les deployments sont une abstraction pour scaler ou mettre à jours des groupes de pods (un peu comme les tasks dans Swarm).
Une autre solution très à la mode depuis 4 ans. Un buzz word du DevOps en France :)
Une solution robuste, structurante et open source d’orchestration Docker.
Au cœur du consortium Cloud Native Computing Foundation très influent dans le monde de l’informatique.
Hébergeable de façon identique dans le cloud, on-premise ou en mixte.
Kubernetes a un flat network (un overlay de plus bas niveau que Swarm) : https://neuvector.com/network-security/kubernetes-networking/
Initialisez Swarm avec docker swarm init.
A l’aide de docker service create, créer un service à partir de l’image traefik/whoami accessible sur le port 9999 et connecté au port 80 et avec 5 répliques.
Accédez à votre service et actualisez plusieurs fois la page. Les informations affichées changent. Pourquoi ?
service scale pour changer le nombre de replicas de votre service et observez le changement avec docker service ps helloexample-voting-appCloner l’application example-voting-app ici : https://github.com/dockersamples/example-voting-app
Lire le schéma d’architecture de l’app example-voting-app sur Github. A noter que le service worker existe en deux versions utilisant un langage de programmation différent (Java ou .NET), et que tous les services possèdent des images pour conteneurs Windows et pour conteneurs Linux. Ces versions peuvent être déployées de manière interchangeable et ne modifient pas le fonctionnement de l’application multi-conteneur. C’est une démonstration de l’utilité du paradigme de la conteneurisation et de l’architecture dite “micro-service”.
Lire attentivement les fichiers docker-compose.yml, docker-compose-simple.yml, docker-stack-simple.yml et docker-stack.yml. Ce sont tous des fichiers Docker Compose classiques avec différentes options liées à un déploiement via Swarm. Quelles options semblent spécifiques à Docker Swarm ? Ces options permettent de configurer des fonctionnalités d'orchestration.
Dessiner rapidement le schéma d’architecture associé au fichier docker-compose-simple.yml, puis celui associé à docker-stack.yml en indiquant bien à quel réseau quel service appartient.
Avec docker swarm init, transformer son installation Docker en une installation Docker compatible avec Swarm. Lisez attentivement le message qui vous est renvoyé.
Déployer la stack du fichier docker-stack.yml : docker stack deploy --compose-file docker-stack.yml vote
docker stack ls indique 6 services pour la stack vote. Observer également l’output de docker stack ps vote et de docker stack services vote. Qu’est-ce qu’un service dans la terminologie de Swarm ?
Accéder aux différents front-ends de la stack grâce aux informations contenues dans les commandes précédentes. Sur le front-end lié au vote, actualiser plusieurs fois la page. Que signifie la ligne Processed by container ID […] ? Pourquoi varie-t-elle ?
Scaler la stack en ajoutant des replicas du front-end lié au vote avec l’aide de docker service --help. Accédez à ce front-end et vérifier que cela a bien fonctionné en actualisant plusieurs fois.
Se grouper par 2 ou 3 pour créer un cluster à partir de vos VM respectives (il faut utiliser une commande Swarm pour récupérer les instructions nécessaires).
Si grouper plusieurs des VM n’est pas possible, vous pouvez créer un cluster multi-nodes très simplement avec l’interface du site Play With Docker, il faut s’y connecter avec vos identifiants Docker Hub.
Vous pouvez faire docker swarm --help pour obtenir des infos manquantes, ou faire docker swarm leave --force pour réinitialiser votre configuration Docker Swarm si besoin.
N’hésitez pas à regarder dans les logs avec systemctl status docker comment se passe l’élection du nœud leader, à partir du moment où vous avez plus d’un manager.
Lancez le service suivant :
docker service create --name whoami --replicas 5 --publish published=80,target=80 traefik/whoami
Accédez au service depuis un node, et depuis l’autre. Actualisez plusieurs fois la page. Les informations affichées changent. Lesquelles, et pourquoi ?
example-voting-appSi besoin, cloner de nouveau le dépôt de l’application example-voting-appavec git clone https://github.com/dockersamples/example-voting-app puis déployez la stack de votre choix.
Ajouter dans le Compose file des instructions pour scaler différemment deux services (3 replicas pour le service front par exemple). N’oubliez pas de redéployer votre Compose file.
puis spécifier quelques options d’orchestration exclusives à Docker Swarm : que fait mode: global ? N’oubliez pas de redéployer votre Compose file.
Avec Portainer ou avec docker-swarm-visualizer, explorer le cluster ainsi créé (le fichier docker-stack.yml de l’app example-voting-app contient déjà un exemplaire de docker-swarm-visualizer).
Trouver la commande pour déchoir et promouvoir l’un de vos nœuds de manager à worker et vice-versa.
Puis sortir un nœud du cluster (drain) : docker node update --availability drain <node-name>
example-voting-appVous avez remarqué ? Nous avons déployé une super stack d’application de vote avec succès mais, si vous testez le vote, vous verrez que ça ne marche pas, il n’est pas comptabilisé. Outre le fait que c’est un plaidoyer vivant contre le vote électronique, vous pourriez tenter de débugger ça maintenant (c’est plutôt facile).
Le fichier kube-deployment.yml de l’app example-voting-app décrit la même app pour un déploiement dans Kubernetes plutôt que dans Docker Compose ou Docker Swarm. Tentez de retrouver quelques équivalences entre Docker Compose / Swarm et Kubernetes en lisant attentivement ce fichier qui décrit un déploiement Kubernetes.
Vous pouvez désormais faire l’exercice 2 du TP 7 pour configurer un serveur web qui permet d’accéder à vos services Swarm via des domaines spécifiques.

Avec Elasticsearch, Filebeat et Kibana… grâce aux labels sur les conteneurs Docker
Avec Traefik, aussi grâce aux labels sur les conteneurs Docker
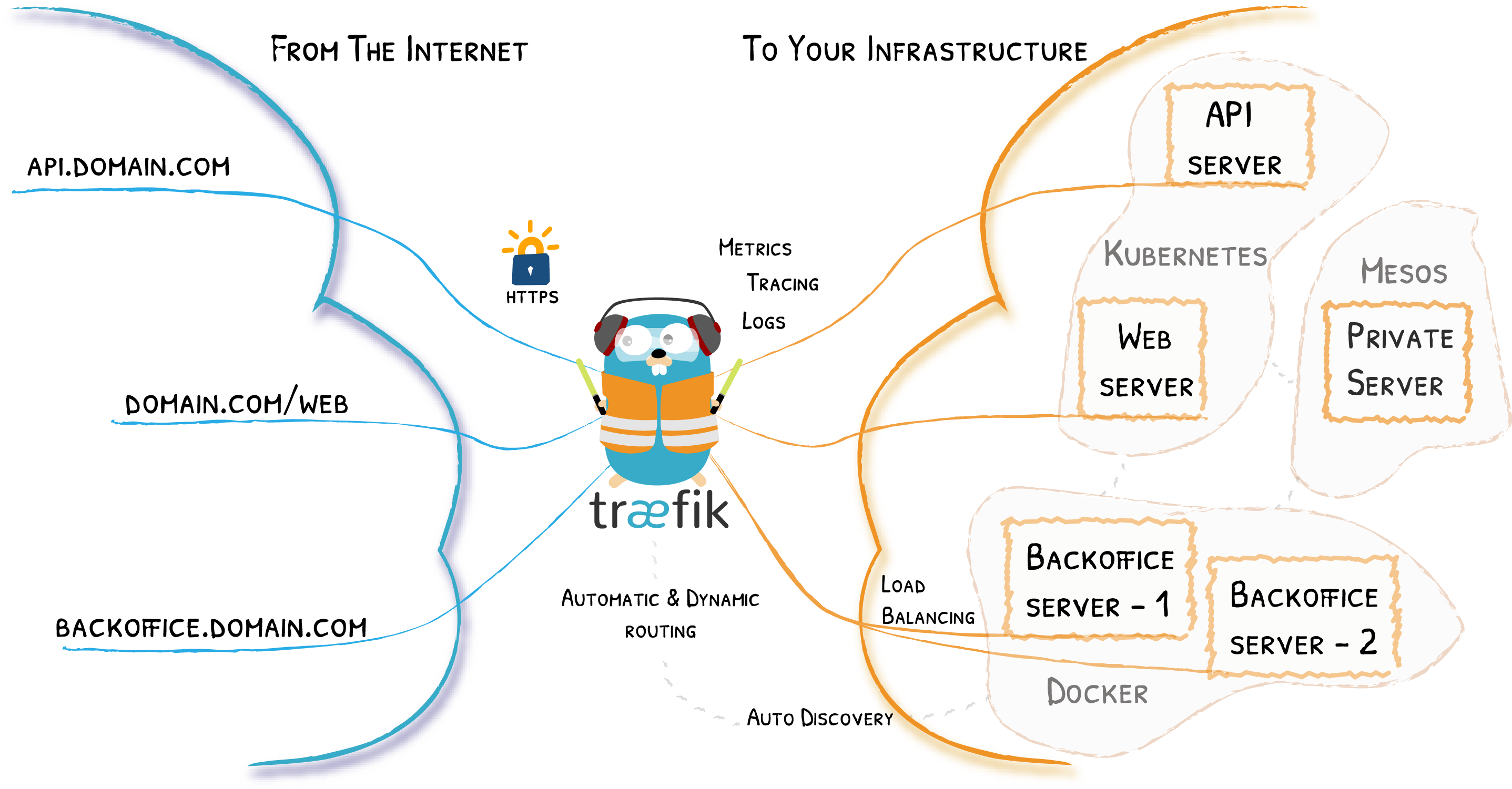
Ansible comme source de healthcheck
un conteneur privilégié est root sur la machine !
des cgroups correct : ulimit -a
par défaut les user namespaces ne sont pas utilisés !
le benchmark Docker CIS : https://github.com/docker/docker-bench-security/
La sécurité de Docker c’est aussi celle de la chaîne de dépendance, des images, des packages installés dans celles-ci : on fait confiance à trop de petites briques dont on ne vérifie pas la provenance ou la mise à jour
docker-socket-proxy : protéger la socket Docker quand on a besoin de la partager à des conteneurs comme Traefik ou Portainer
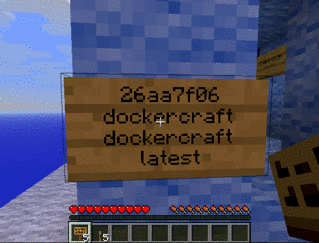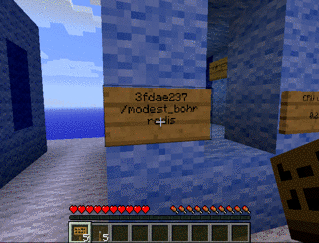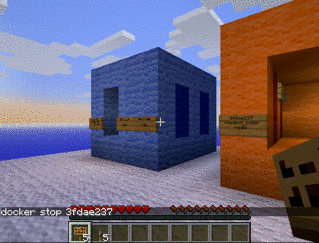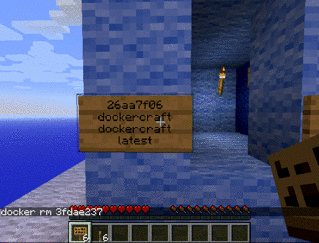 Dockercraft : administrez vos containers dans Minecraft
Dockercraft : administrez vos containers dans Minecraft
microblog, dnmonster ou l’app healthcheck vue au TP2)..gitlab-ci.yml depuis l’interface web de Gitlab et choisissez “Docker” comme template. Observons-le ensemble attentivement.docker build de la documentation GitlabBitBucket propose aussi son outil de pipeline, à la différence qu’il n’a pas de registry intégré, le template par défaut propose donc de pousser son image sur le registry Docker Hub.
DOCKERHUB_USERNAME, DOCKERHUB_PASSWORD et DOCKERHUB_NAMESPACE (identique à l’username ici).Nous avons fait la partie CI (intégration continue). Une étape supplémentaire est nécessaire pour ajouter le déploiement continu de l’app (CD) : si aucune étape précédente n’a échoué, la nouvelle version de l’app devra être déployée sur votre serveur, via une connexion SSH et rsync par exemple.
Il faudra ajouter des variables secrètes au projet (clé SSH privée par exemple), cela se fait dans les options de Gitlab ou de BitBucket.
Traefik est un reverse proxy très bien intégré à Docker. Il permet de configurer un routage entre un point d’entrée (ports 80 et 443 de l’hôte) et des containers Docker, grâce aux informations du daemon Docker et aux labels sur chaque containers.
Nous allons nous baser sur le guide d’introduction Traefik - Getting started.
Explorez le dashboard Traefik accessible sur le port indiqué dans le fichier Docker Compose.
Ajouter des labels à l’app web que vous souhaitez desservir grâce à Traefik à partir de l’exemple de la doc Traefik, grâce aux labels ajoutés dans le docker-compose.yml (attention à l’indentation).
Avec l’aide de la documentation Traefik sur Let’s Encrypt et Docker Compose, configurez Traefik pour qu’il crée un certificat Let’s Encrypt pour votre container.
Si vous avez une IP publique mais pas de domaine, vous pouvez utiliser le service gratuit [netlib.re] qui vous fournira un domaine en *.netlib.re.
Vous aurez aussi besoin de configurer des DNS via netlib.re si vous voulez vérifier des sous-domaines (et non votre domaine principal) auprès de Let’s Encrypt (de plus, si vous voulez un certificat avec wildcard pour tous vos sous-domaines, il faudra résoudre le dnsChallenge de Let’s Encrypt de manière manuelle).
Quelle est la principale différence entre une machine virtuelle (VM) et un conteneur ?
En quoi Docker permet de faire de l'Infrastructure as Code ?
Quels sont les principaux atouts de Docker ?
Pour créer un conteneur Docker à partir du code d’un logiciel il faut d’abord :
Un volume Docker est :
Indiquez la ou les affirmations vraies :
Comment configurer de préférence un conteneur à sa création (lancement avec docker run) ?
docker exec puis aller modifier les fichiers de configuration à l’intérieurUn Compose file ou fichier Compose permet :
Indiquez la ou les affirmations vraies :
La philosophie de Docker est basée sur :
Indiquez la ou les affirmations vraies :
Docker Swarm est :
Administrer des applications multiconteneurs complexes
Kubernetes est la solution dominante d’orchestration de conteneurs développée en Open Source au sein de la Cloud Native Computing Foundation.
![]()
Kubernetes est un orchestrateur développé originellement par Google et basé sur une dizaine d’années d’expérience de déploiement d’application énormes.
La première version est sortie en 2014 et K8S est devenu depuis l’un des projets open source les plus populaires du monde.
Autour de ce projet s’est développée la Cloud Native Computing Foundation qui comprend : Google, CoreOS, Mesosphere, Red Hat, Twitter, Huawei, Intel, Cisco, IBM, Docker, Univa et VMware.
Il s’agit d’une solution robuste, structurante et open source qui se construit autour des objectifs de:
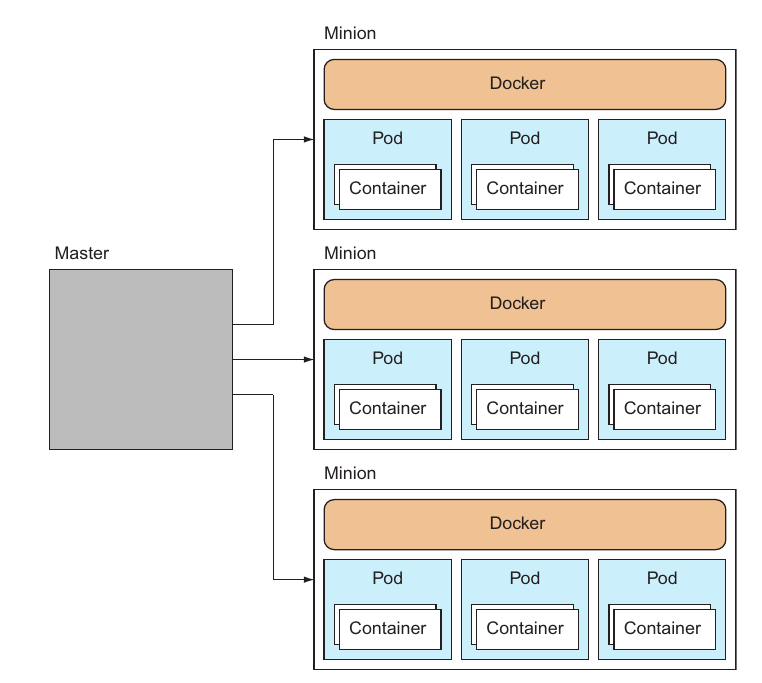
Une difficulté à manier tout ce qui est stateful, comme des bases de données
Beaucoup de points sont laissés à la décision du fournisseur de cloud ou des admins système :
Pas de solution de stockage par défaut, et parfois difficile de stocker “simplement” sans passer par les fournisseurs de cloud, ou par une solution de stockage décentralisé à part entière (Ceph, Gluster, Longhorn…)
Beaucoup de solutions de réseau qui se concurrencent, demandant un comparatif fastidieux
Pas de solution de loadbalancing par défaut : soit on se base sur le fournisseur de cloud, soit on configure MetalLB
Kubernetes n’est qu’un ensemble de standards. Il existe beaucoup de variétés (flavours) de Kubernetes, implémentant concrètement les solutions techniques derrière tout ce que Kubernetes ne fait que définir : solutions réseau, stockage (distribué ou non), loadbalancing, service de reverse proxy (Ingress), autoscaling de cluster (ajout de nouvelles VM au cluster automatiquement), monitoring…
Il est très possible de monter un cluster Kubernetes en dehors de ces fournisseurs, mais cela demande de faire des choix (ou bien une solution opinionated ouverte comme Rancher) et une relative maîtrise d’un nombre varié de sujets (bases de données, solutions de loadbalancing, redondance du stockage…).
C’est là la relative hypocrisie de Kubernetes : tout est ouvert et standardisé, mais devant la (relative) complexité et connaissance nécessaire pour mettre en place sa propre solution (de stockage distribué par exemple), nous retombons rapidement dans la facilité et les griffes du vendor lock-in (enfermement propriétaire).
L’écosystème Kubernetes développé par Google. Très populaire car très flexible tout en étant l’implémentation de référence de Kubernetes.
Un écosystème Kubernetes axé sur l’intégration avec les services du cloud Azure (stockage, registry, réseau, monitoring, services de calcul, loadbalancing, bases de données…).
Un écosystème Kubernetes assez standard à la sauce Amazon axé sur l’intégration avec le cloud Amazon (la gestion de l’accès, des loadbalancers ou du scaling notamment, le stockage avec Amazon EBS, etc.)
Un écosystème Kubernetes très complet, assez opinionated et entièrement open-source, non lié à un fournisseur de cloud. Inclut l’installation de stack de monitoring (Prometheus), de logging, de réseau mesh (Istio) via une interface web agréable. Rancher maintient aussi de nombreuses solutions open source, comme par exemple Longhorn pour le stockage distribué.
Un écosystème Kubernetes fait par l’entreprise Rancher et axé sur la légèreté. Il remplace etcd par une base de données Postgres, utilise Traefik pour l’ingress et Klipper pour le loadbalancing.
Une version de Kubernetes configurée et optimisée par Red Hat pour être utilisée dans son écosystème. Tout est intégré donc plus guidé, avec l’inconvénient d’être un peu captif·ve de l’écosystème et des services vendus par Red Hat.
Mesos est une solution plus générale que Kubernetes pour exécuter des applications distribuées. En combinant Mesos avec son “application framework” Marathon on obtient une solution équivalente sur de nombreux points à Kubernetes.
Elle est cependant moins standard : - Moins de ressources disponibles pour apprendre, intégrer avec d’autre solution etc. - Peu vendu en tant que service par les principaux cloud provider. - Plus chère à mettre en oeuvre.
Comparaison d’architecture : Mesos vs. Kubernetes
Kubernetes décrit ses ressources en YAML. A quoi ça ressemble, YAML ?
- marché:
lieu: Marché de la Place
jour: jeudi
horaire:
unité: "heure"
min: 12
max: 20
fruits:
- nom: pomme
couleur: "verte"
pesticide: avec
- nom: poires
couleur: jaune
pesticide: sans
légumes:
- courgettes
- salade
- potiron
Alignement ! (2 espaces !!)
ALIGNEMENT !! (comme en python)
ALIGNEMENT !!! (le défaut du YAML, pas de correcteur syntaxique automatique, c’est bête mais vous y perdrez forcément du temps !)
des listes (tirets)
des paires clé: valeur
Un peu comme du JSON, avec cette grosse différence que le JSON se fiche de l’alignement et met des accolades et des points-virgules
les extensions Kubernetes et YAML dans VSCode vous aident à repérer des erreurs
Le Kubernetes master est responsable du maintien de l’état souhaité pour votre cluster. Lorsque vous interagissez avec Kubernetes, par exemple en utilisant l’interface en ligne de commande kubectl, vous communiquez avec le master Kubernetes de votre cluster.
Le “master” fait référence à un ensemble de processus gérant l’état du cluster. Le master peut également être répliqué pour la disponibilité et la redondance.
Les nœuds d’un cluster sont les machines (serveurs physiques, machines virtuelles, etc.) qui exécutent vos applications et vos workflows. Le master node Kubernetes contrôle chaque noeud; vous interagirez rarement directement avec les nœuds.
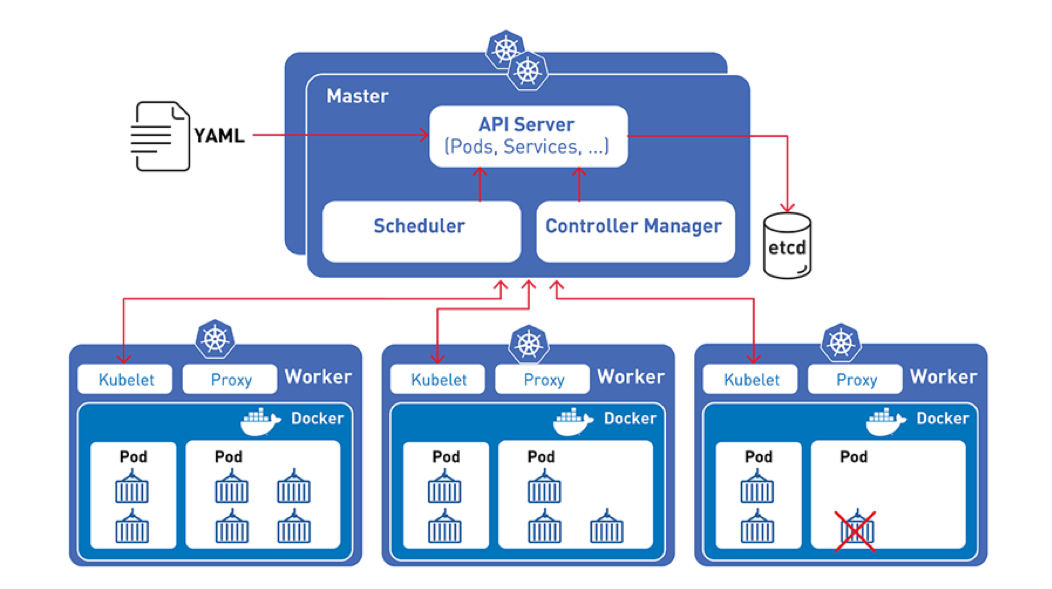
Pour utiliser Kubernetes, vous utilisez les objets de l’API Kubernetes pour décrire l’état souhaité de votre cluster: quelles applications ou autres processus que vous souhaitez exécuter, quelles images de conteneur elles utilisent, le nombre de réplicas, les ressources réseau et disque que vous mettez à disposition, et plus encore.
Vous définissez l’état souhaité en créant des objets à l’aide de l’API Kubernetes, généralement via l’interface en ligne de commande, kubectl. Vous pouvez également utiliser l’API Kubernetes directement pour interagir avec le cluster et définir ou modifier l’état souhaité.
Une fois que vous avez défini l’état souhaité, le plan de contrôle Kubernetes (control plane) permet de faire en sorte que l’état actuel du cluster corresponde à l’état souhaité. Pour ce faire, Kubernetes effectue automatiquement diverses tâches, telles que le démarrage ou le redémarrage de conteneurs, la mise à jour du nombre de replicas d’une application donnée, etc.
Le control plane Kubernetes comprend un ensemble de processus en cours d’exécution sur votre cluster:
Le master Kubernetes est un ensemble de trois processus qui s’exécutent sur un seul nœud de votre cluster, désigné comme nœud maître (master node en anglais). Ces processus sont:
kube-apiserverkube-controller-managerkube-schedulerChaque nœud non maître de votre cluster exécute deux processus :
kubelet, qui communique avec le Kubernetes master.
kube-proxy, un proxy réseau reflétant les services réseau Kubernetes sur chaque nœud.
Les différentes parties du control plane Kubernetes, telles que les processus Kubernetes master et kubelet, déterminent la manière dont Kubernetes communique avec votre cluster.
Le control plane conserve un enregistrement de tous les objets Kubernetes du système et exécute des boucles de contrôle continues pour gérer l’état de ces objets. À tout moment, les boucles de contrôle du control plane répondent aux modifications du cluster et permettent de faire en sorte que l’état réel de tous les objets du système corresponde à l’état souhaité que vous avez fourni.
Par exemple, lorsque vous utilisez l’API Kubernetes pour créer un objet Deployment, vous fournissez un nouvel état souhaité pour le système. Le control plane Kubernetes enregistre la création de cet objet et exécute vos instructions en lançant les applications requises et en les planifiant vers des nœuds de cluster, afin que l’état actuel du cluster corresponde à l’état souhaité.
kubectlPermet depuis sa machine de travail de contrôler le cluster avec une ligne de commande qui ressemble un peu à celle de Docker (cf. TP1 et TP2):
Cet utilitaire s’installe avec un gestionnaire de paquet classique mais est souvent fourni directement par une distribution de développement de kubernetes.
Nous l’installerons avec snap dans le TP1.
Pour se connecter, kubectl a besoin de l’adresse de l’API Kubernetes, d’un nom d’utilisateur et d’un certificat.
kubeconfigLe fichier kubeconfig par défaut se trouve sur Linux à l’emplacement ~/.kube/config.
On peut aussi préciser la configuration au runtime comme ceci: kubectl --kubeconfig=fichier_kubeconfig.yaml <commandes_k8s>
Le même fichier kubeconfig peut stocker plusieurs configurations dans un fichier YAML :
Exemple :
apiVersion: v1
clusters:
- cluster:
certificate-authority: /home/jacky/.minikube/ca.crt
server: https://172.17.0.2:8443
name: minikube
- cluster:
certificate-authority-data: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSURKekNDQWcrZ0F3SUJBZ0lDQm5Vd0RRWUpLb1pJaHZjTkFRRUxCUUF3TXpFVk1CTUdBMVVFQ2hNTVJHbG4KYVhSaGJFOWpaV0Z1TVJvd0dBWURWUVFERXhGck9<clipped>3SCsxYmtGOHcxdWI5eHYyemdXU1F3NTdtdz09Ci0tLS0tRU5EIENFUlRJRklDQVRFLS0tLS0K
server: https://5ba26bee-00f1-4088-ae11-22b6dd058c6e.k8s.ondigitalocean.com
name: do-lon1-k8s-tp-cluster
contexts:
- context:
cluster: minikube
user: minikube
name: minikube
- context:
cluster: do-lon1-k8s-tp-cluster
user: do-lon1-k8s-tp-cluster-admin
name: do-lon1-k8s-tp-cluster
current-context: do-lon1-k8s-tp-cluster
kind: Config
preferences: {}
users:
- name: do-lon1-k8s-tp-cluster-admin
user:
token: 8b2d33e45b980c8642105ec827f41ad343e8185f6b4526a481e312822d634aa4
- name: minikube
user:
client-certificate: /home/jacky/.minikube/profiles/minikube/client.crt
client-key: /home/jacky/.minikube/profiles/minikube/client.key
Ce fichier déclare 2 clusters (un local, un distant), 2 contextes et 2 users.
Pour installer un cluster de développement :
k3s, de RancherkubeadmInstaller un cluster de production Kubernetes à la main est nettement plus complexe que mettre en place un cluster Docker Swarm.
Kubelet sur tous les noeudskubeadm sur un noeud masterkubeadmflannel (d’autres sont possible et le choix vous revient)etcd avec kubeadmL’installation est décrite dans la documentation officielle
On peut également installer Kubernetes de façon encore plus manuelle soit pour déployer une configuration vraiment spécifique ou simplement pour mieux comprendre ses rouages et composants.
Ce type d’installation est décrite par exemple ici : Kubernetes the hard way.
Tous les principaux provider de cloud fournissent depuis plus ou moins longtemps des solutions de cluster gérées par eux :
Au cours de nos TPs nous allons passer rapidement en revue deux manières de mettre en place Kubernetes :
minikubeNous allons d’abord passer par la première option.
kubectlkubectl est le point d’entré universel pour contrôler tous les type de cluster kubernetes. C’est un client en ligne de commande qui communique en REST avec l’API d’un cluster.
Nous allons explorer kubectl au fur et à mesure des TPs. Cependant à noter que :
kubectl peut gérer plusieurs clusters/configurations et switcher entre ces configurationskubectl est nécessaire pour le client graphique Lens que nous utiliserons plus tard.La méthode d’installation importe peu. Pour installer kubectl sur Ubuntu nous ferons simplement: sudo snap install kubectl --classic.
kubectl version pour afficher la version du client kubectl.Minikube est la version de développement de Kubernetes (en local) la plus répendue. Elle est maintenue par la cloud native foundation et très proche de kubernetes upstream. Elle permet de simuler un ou plusieurs noeuds de cluster sous forme de conteneurs docker ou de machines virtuelles.
Nous utiliserons classiquement docker comme runtime pour minikube (les noeuds k8s seront des conteneurs simulant des serveurs). Ceci est, bien sur, une configuration de développement. Elle se comporte cependant de façon très proche d’un véritable cluster.
Si Docker n’est pas installé, installer Docker avec la commande en une seule ligne : curl -fsSL https://get.docker.com | sh, puis ajoutez-vous au groupe Docker avec sudo usermod -a -G docker <votrenom>, et faites sudo reboot pour que cela prenne effet.
Pour lancer le cluster faites simplement: minikube start (il est également possible de préciser le nombre de coeurs de calcul, la mémoire et et d’autre paramètre pour adapter le cluster à nos besoins.)
Minikube configure automatiquement kubectl (dans le fichier ~/.kube/config) pour qu’on puisse se connecter au cluster de développement.
kubectl get nodes.Affichez à nouveau la version kubectl version. Cette fois-ci la version de kubernetes qui tourne sur le cluster actif est également affichée. Idéalement le client et le cluster devrait être dans la même version mineure par exemple 1.20.x.
Pour permettre à kubectl de compléter le nom des commandes et ressources avec <Tab> il est utile d’installer l’autocomplétion pour Bash :
sudo apt install bash-completion
source <(kubectl completion bash)
echo "source <(kubectl completion bash)" >> ${HOME}/.bashrc
Vous pouvez désormais appuyer sur <Tab> pour compléter vos commandes kubectl, c’est très utile !
Notre cluster k8s est plein d’objets divers, organisés entre eux de façon dynamique pour décrire des applications, tâches de calcul, services et droits d’accès. La première étape consiste à explorer un peu le cluster :
kubectl get nodes) puis affichez ses caractéristiques avec kubectl describe node/minikube.La commande get est générique et peut être utilisée pour récupérer la liste de tous les types de ressources.
De même, la commande describe peut s’appliquer à tout objet k8s. On doit cependant préfixer le nom de l’objet par son type (ex : node/minikube ou nodes minikube) car k8s ne peut pas deviner ce que l’on cherche quand plusieurs ressources ont le même nom.
kubectl get allNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 2m34s
Il semble qu’il n’y a qu’une ressource dans notre cluster. Il s’agit du service d’API Kubernetes, pour qu’on puisse communiquer avec le cluster.
En réalité il y en a généralement d’autres cachés dans les autres namespaces. En effet les éléments internes de Kubernetes tournent eux-mêmes sous forme de services et de daemons Kubernetes. Les namespaces sont des groupes qui servent à isoler les ressources de façon logique et en termes de droits (avec le Role-Based Access Control (RBAC) de Kubernetes).
Pour vérifier cela on peut :
kubectl get namespacesUn cluster Kubernetes a généralement un namespace appelé default dans lequel les commandes sont lancées et les ressources créées si on ne précise rien. Il a également aussi un namespace kube-system dans lequel résident les processus et ressources système de k8s. Pour préciser le namespace on peut rajouter l’argument -n à la plupart des commandes k8s.
Pour lister les ressources liées au kubectl get all -n kube-system.
Ou encore : kubectl get all --all-namespaces (peut être abrégé en kubectl get all -A) qui permet d’afficher le contenu de tous les namespaces en même temps.
Pour avoir des informations sur un namespace : kubectl describe namespace/kube-system
Nous allons maintenant déployer une première application conteneurisée. Le déploiement est plus complexe qu’avec Docker (et Swarm), en particulier car il est séparé en plusieurs objets et plus configurable.
kubectl create deployment microbot --image=monachus/rancher-demo.Cette commande crée un objet de type deployment. Nous pourvons étudier ce deployment avec la commande kubectl describe deployment/microbot.
kubectl scale deployment microbot --replicas=5kubectl describe deployment/microbot permet de constater que le service est bien passé à 5 replicas.A ce stade le déploiement n’est pas encore accessible de l’extérieur du cluster pour cela nous devons l’exposer en tant que service :
kubectl expose deployment microbot --type=NodePort --port=8080 --name=microbot-servicekubectl get servicesUn service permet d’exposer un déploiement soit par port soit grâce à un loadbalancer.
Pour exposer cette application sur le port de notre choix, nous devrions avoir recours à un LoadBalancer.
Nous verrons cela plus en détail dans le TP2.
Nous ne verrons pas ça ici (il faudrait utiliser l’addon MetalLB de Minikube).
Mais nous pouvons quand même lancer une commande dans notre environnement de dev :
kubectl port-forward svc/microbot-service 8080:8080 --address 0.0.0.0
Vous pouvez désormais accéder à votre app via :
http://localhost:8080
Minikube intègre aussi une façon d’accéder à notre service : c’est la commande minikube service microbot-service
Sauriez-vous expliquer ce que l’app fait ?
Pour gagner du temps on dans les commandes Kubernetes on définit généralement un alias: alias kc='kubectl' (à mettre dans votre .bash_profile en faisant echo "alias kc='kubectl'" >> ~/.bash_profile, puis en faisant source ~/.bash_profile).
Vous pouvez ensuite remplacer kubectl par kc dans les commandes.
Également pour gagner du temps en ligne de commande, la plupart des mots-clés de type Kubernetes peuvent être abrégés :
services devient svcdeployments devient deployLa liste complète : https://blog.heptio.com/kubectl-resource-short-names-heptioprotip-c8eff9fb7202
Lens est une interface graphique sympatique pour Kubernetes.
Elle se connecte en utilisant la configuration ~/.kube/config par défaut et nous permettra d’accéder à un dashboard bien plus agréable à utiliser.
Vous pouvez l’installer en lançant ces commandes :
sudo apt-get update; sudo apt-get install -y libxss-dev
curl -fSL https://github.com/lensapp/lens/releases/download/v4.0.6/Lens-4.0.6.AppImage -o ~/Lens.AppImage
chmod +x ~/Lens.AppImage
~/Lens.AppImage &
La création prend environ 5 minutes.
kubeconfig. (download the cluster configuration file, ou bien Download Config File).kubeconfig (Download Kubeconfig).Ce fichier contient la configuration kubectl adaptée pour la connexion à notre cluster.
Ouvrez avec gedit les fichiers kubeconfig et ~/.kube/config.
fusionnez dans ~/.kube/config les éléments des listes YAML de:
clusterscontextsusersmettez la clé current-context: à <nom_cluster> (compléter avec votre valeur)
Testons la connection avec kubectl get nodes.
kubectl cluster-info, l’API du cluster est accessible depuis un nom de domaine généré par le provider.microbot comme dans la partie précédente avec minikubeService, ou sur la page du fournisseur de cloud.On veut que le service soit tout le temps accessible même lorsque certaines ressources manquent :
Pour cela on doit avoir des ressources multiples…
Il faut que les ressources disponibles prennent automatiquement le relais des ressources indisponibles. Pour cela on utilise généralement:
Mais aussi :
Nous allons voir que Kubernetes intègre automatiquement les principes de load balancing et de healthcheck dans l’orchestration de conteneurs
Cas d’usage :
L’objectif est de permettre la haute disponibilité : on veut que notre service soit toujours disponible, même en période de panne/maintenance.
Donc on va dupliquer chaque partie de notre service et mettre les différentes instances derrière un load balancer.
Le load balancer va vérifier pour chaque backend s’il est disponible (healthcheck) avant de rediriger le trafic.
Répartition géographique : en fonction de la provenance des requêtes on va rediriger vers un datacenter adapté (+ proche).
Fournir à l’application une façon d’indiquer qu’elle est disponible, c’est-à-dire :
Classiquement, les applications ne sont pas informées du contexte dans lequel elles tournent : la configuration doit être opérée de l’extérieur de l’application.
Mais dans un environnement hautement dynamique comme Kubernetes, la configuration externe ne suffit pas pour gérer des applications complexes distribuées qui doivent se déployer régulièrement, se parler et parler avec l’extérieur.
La découverte de service désigne généralement les méthodes qui permettent à un programme de chercher autour de lui (généralement sur le réseau ou dans l’environnement) ce dont il a besoin.
Concrètement, au sein d’un orchestrateur, un système de découverte de service est un serveur qui est au courant automatiquement :
Ensuite il suffit aux applications de pouvoir interroger ce serveur pour s’autoconfigurer.
Un exemple historique de découverte de service est le DNS : on fait une requête vers un serveur spécial pour retrouver une adresse IP (on découvre le serveur dont on a besoin). Cependant le DNS n’a pas été pensé pour ça :
Il existe deux types de stratégies de rollout native à Kubernetes :
Recreate : arrêter les pods avec l’ancienne version en même temps et créer les nouveaux simultanémentRollingUpdate : mise à jour continue, arrêt des anciens pods les uns après les autres et création des nouveaux au fur et à mesure (paramétrable)Mais il existe un panel de stratégies plus large pour updater ses apps :
Source : https://blog.container-solutions.com/kubernetes-deployment-strategies
Utiliser Kubernetes consiste à déclarer des objets grâce à l’API Kubernetes pour décrire l’état souhaité d’un cluster : quelles applications ou autres processus exécuter, quelles images elles utilisent, le nombre de replicas, les ressources réseau et disque que vous mettez à disposition, etc.
On définit des objets généralement via l’interface en ligne de commande et kubectl de deux façons :
kubectl run <conteneur> ..., kubectl expose ...kubectl apply -f monpod.ymlVous pouvez également écrire des programmes qui utilisent directement l’API Kubernetes pour interagir avec le cluster et définir ou modifier l’état souhaité. Kubernetes est complètement automatisable !
applyKubernetes encourage le principe de l’infrastructure-as-code : il est recommandé d’utiliser une description YAML et versionnée des objets et configurations Kubernetes plutôt que la CLI.
Pour cela la commande de base est kubectl apply -f object.yaml.
La commande inverse kubectl delete -f object.yaml permet de détruire un objet précédement appliqué dans le cluster à partir de sa description.
Lorsqu’on vient d’appliquer une description on peut l’afficher dans le terminal avec kubectl apply -f myobj.yaml view-last-applied
Globalement Kubernetes garde un historique de toutes les transformations des objets : on peut explorer, par exemple avec la commande kubectl rollout history deployment.
Les description YAML permettent de décrire de façon lisible et manipulable de nombreuses caractéristiques des ressources Kubernetes (un peu comme un Compose file par rapport à la CLI Docker).
Création d’un service simple :
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
ports:
- port: 443
targetPort: 8443
selector:
k8s-app: kubernetes-dashboard
type: NodePort
Création d’un “compte utiliseur” ServiceAccount
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
Remarques de syntaxe :
Toutes les descriptions doivent commencer par spécifier la version d’API (minimale) selon laquelle les objets sont censés être créés
Il faut également préciser le type d’objet avec kind
Le nom dans metadata:\n name: value est également obligatoire.
On rajoute généralement une description longue démarrant par spec:
On peut mettre plusieurs ressources à la suite dans un fichier k8s : cela permet de décrire une installation complexe en un seul fichier
L’ordre n’importe pas car les ressources sont décrites déclarativement c’est-à-dire que:
On peut sauter des lignes dans le YAML et rendre plus lisible les descriptions
On sépare les différents objets par ---
Tous les objets Kubernetes sont rangés dans différents espaces de travail isolés appelés namespaces.
Cette isolation permet 3 choses :
Lorsqu’on lit ou créé des objets sans préciser le namespace, ces objets sont liés au namespace default.
Pour utiliser un namespace autre que default avec kubectl il faut :
-n : kubectl get pods -n kube-systemKubernetes gère lui-même ses composants internes sous forme de pods et services.
-A ou --all-namespacesUn Pod est l’unité d’exécution de base d’une application Kubernetes que vous créez ou déployez. Un Pod représente des process en cours d’exécution dans votre Cluster.
Un Pod encapsule un conteneur (ou souvent plusieurs conteneurs), des ressources de stockage, une IP réseau unique, et des options qui contrôlent comment le ou les conteneurs doivent s’exécuter (ex: restart policy). Cette collection de conteneurs et volumes tournent dans le même environnement d’exécution mais les processus sont isolés.
Un Pod représente une unité de déploiement : un petit nombre de conteneurs qui sont étroitement liés et qui partagent :
Chaque Pod est destiné à exécuter une instance unique d’un workload donné. Si vous désirez mettre à l’échelle votre workload, vous devez multiplier le nombre de Pods.
Pour plus de détail sur la philosophie des pods, vous pouvez consulter ce bon article.
Kubernetes fournit un ensemble de commande pour débugger des conteneurs :
kubectl logs <pod-name> -c <conteneur_name> (le nom du conteneur est inutile si un seul)kubectl exec -it <pod-name> -c <conteneur_name> -- bashkubectl attach -it <pod-name>Enfin, pour debugger la sortie réseau d’un programme on peut rapidement forwarder un port depuis un pods vers l’extérieur du cluster :
kubectl port-forward <pod-name> <port_interne>:<port_externe>NodePort.Pour copier un fichier dans un pod on peut utiliser: kubectl cp <pod-name>:</path/to/remote/file> </path/to/local/file>
Pour monitorer rapidement les ressources consommées par un ensemble de processus il existe les commande kubectl top nodes et kubectl top pods
kuard-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: nom_pod
spec:
containers:
- image: tecpi/pod_image:0.1
name: nom_conteneur
ports:
- containerPort: 8080
name: http
protocol: TCP
Un ReplicaSet ou rs est une ressource qui permet de spécifier finement le nombre de réplication d’un pod à un moment donné.
kubectl get rs pour afficher la liste des replicas.En général on ne les manipule pas directement.
Plutôt que d’utiliser les replicasets il est recommander d’utiliser un objet de plus haut niveau : les deployments.
De la même façon que les ReplicaSets gèrent les pods, les Deployments gèrent les ReplicaSet.
Un déploiement sert surtout à gérer le déploiement d’une nouvelle version d’un pod.
Un deployment est un peu l’équivalent d’un service docker : il demande la création d’un ensemble de Pods désignés par une étiquette label.
Exemple :
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
strategy:
type: Recreate
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
Pour les afficher : kubectl get deployments
La commande kubectl run sert à créer un deployment à partir d’un modèle. Il vaut mieux utilisez apply -f.
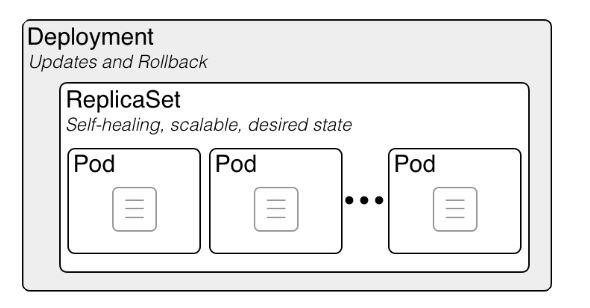 Les poupées russes Kubernetes : un Deployment contient un ReplicaSet, qui contient des Pods, qui contiennent des conteneurs
Les poupées russes Kubernetes : un Deployment contient un ReplicaSet, qui contient des Pods, qui contiennent des conteneurs
Dans Kubernetes, un service est un objet qui :
L’ensemble des pods ciblés par un service est déterminé par un selector.
Par exemple, considérons un backend de traitement d’image (stateless, c’est-à-dire ici sans base de données) qui s’exécute avec 3 replicas. Ces replicas sont interchangeables et les frontends ne se soucient pas du backend qu’ils utilisent. Bien que les pods réels qui composent l’ensemble backend puissent changer, les clients frontends ne devraient pas avoir besoin de le savoir, pas plus qu’ils ne doivent suivre eux-mêmes l’état de l’ensemble des backends.
L’abstraction du service permet ce découplage : les clients frontend s’addressent à une seule IP avec un seul port dès qu’ils ont besoin d’avoir recours à un backend. Les backends vont recevoir la requête du frontend aléatoirement.
Les Services sont de trois types principaux :
ClusterIP: expose le service sur une IP interne au cluster appelée ClusterIP. Les autres pods peuvent alors accéder au service mais pas l’extérieur.
NodePort: expose le service depuis l’IP publique de chacun des noeuds du cluster en ouvrant port directement sur le nœud, entre 30000 et 32767. Cela permet d’accéder aux pods internes répliqués. Comme l’IP est stable on peut faire pointer un DNS ou Loadbalancer classique dessus.
LoadBalancer: expose le service en externe à l’aide d’un Loadbalancer de fournisseur de cloud. Les services NodePort et ClusterIP, vers lesquels le Loadbalancer est dirigé sont automatiquement créés.Nous allons suivre ce tutoriel pas à pas : https://kubernetes.io/docs/tutorials/stateful-application/mysql-wordpress-persistent-volume/
Il faut :
On peut ensuite observer les différents objets créés, et optimiser le process avec un fichier kustomization.yaml plus complet.
Etudions et lançons ensemble ce YAML :
wordsmith.yml :
apiVersion: v1
kind: Service
metadata:
name: db
labels:
app: words-db
spec:
ports:
- port: 5432
targetPort: 5432
name: db
selector:
app: words-db
clusterIP: None
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: db
labels:
app: words-db
spec:
selector:
matchLabels:
app: words-db
template:
metadata:
labels:
app: words-db
spec:
containers:
- name: db
image: dockersamples/k8s-wordsmith-db
ports:
- containerPort: 5432
name: db
---
apiVersion: v1
kind: Service
metadata:
name: words
labels:
app: words-api
spec:
ports:
- port: 8080
targetPort: 8080
name: api
selector:
app: words-api
clusterIP: None
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: words
labels:
app: words-api
spec:
selector:
matchLabels:
app: words-api
replicas: 5
template:
metadata:
labels:
app: words-api
spec:
containers:
- name: words
image: dockersamples/k8s-wordsmith-api
ports:
- containerPort: 8080
name: api
---
apiVersion: v1
kind: Service
metadata:
name: web
labels:
app: words-web
spec:
ports:
- port: 8081
targetPort: 80
name: web
selector:
app: words-web
type: LoadBalancer
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: web
labels:
app: words-web
spec:
selector:
matchLabels:
app: words-web
template:
metadata:
labels:
app: words-web
spec:
containers:
- name: web
image: dockersamples/k8s-wordsmith-web
ports:
- containerPort: 80
name: words-web
Les solutions réseau dans Kubernetes ne sont pas standard. Il existe plusieurs façons d’implémenter le réseau.
Les Services sont de trois types principaux :
ClusterIP: expose le service sur une IP interne au cluster appelée ClusterIP. Les autres pods peuvent alors accéder au service mais pas l’extérieur.
NodePort: expose le service depuis l’IP publique de chacun des noeuds du cluster en ouvrant port directement sur le nœud, entre 30000 et 32767. Cela permet d’accéder aux pods internes répliqués. Comme l’IP est stable on peut faire pointer un DNS ou Loadbalancer classique dessus.
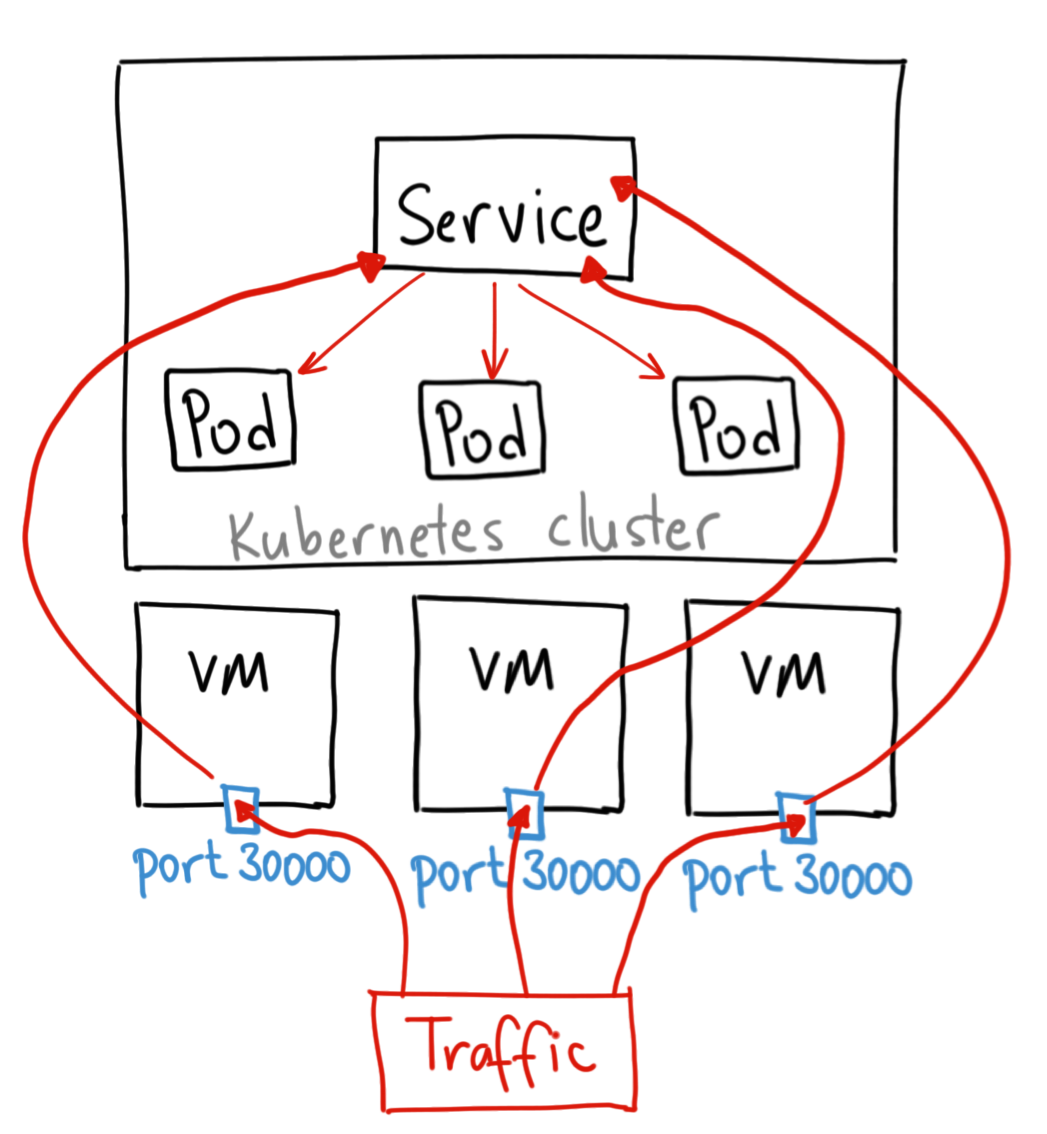 Crédits à Ahmet Alp Balkan pour les schémas
Crédits à Ahmet Alp Balkan pour les schémas
LoadBalancer: expose le service en externe à l’aide d’un Loadbalancer de fournisseur de cloud. Les services NodePort et ClusterIP, vers lesquels le Loadbalancer est dirigé sont automatiquement créés.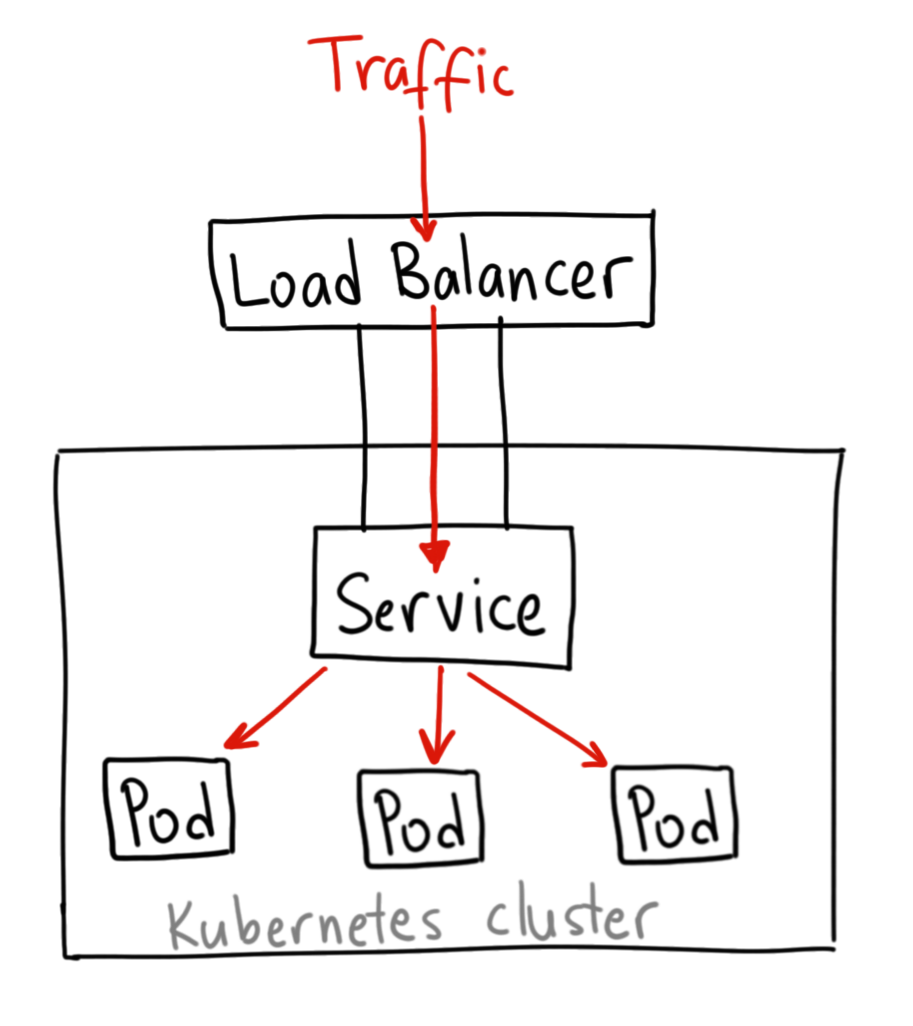 Crédits Ahmet Alp Balkan
Crédits Ahmet Alp Balkan
Beaucoup de solutions de réseau qui se concurrencent, demandant un comparatif un peu fastidieux.
ces implémentations sont souvent concrètement des DaemonSets : des pods qui tournent dans chacun des nodes de Kubernetes
Calico, Flannel, Weave ou Cilium sont très employées et souvent proposées en option par les fournisseurs de cloud
Cilium a la particularité d’utiliser la technologie eBPF de Linux qui permet une sécurité et une rapidité accrue
Comparaisons :
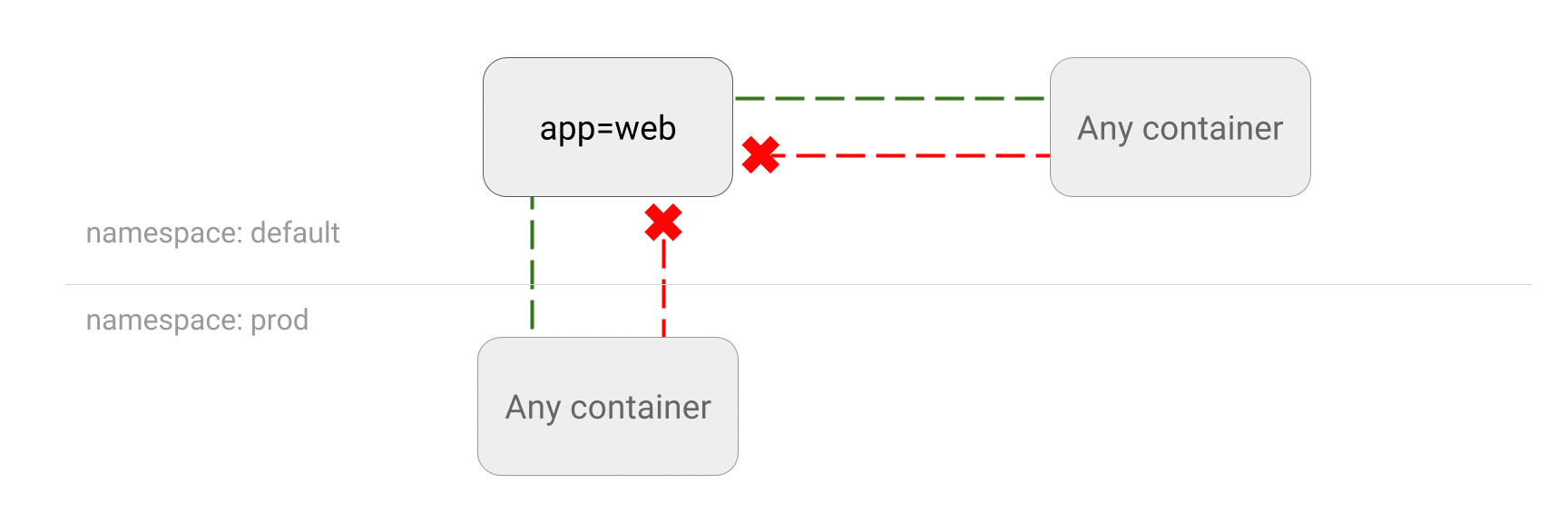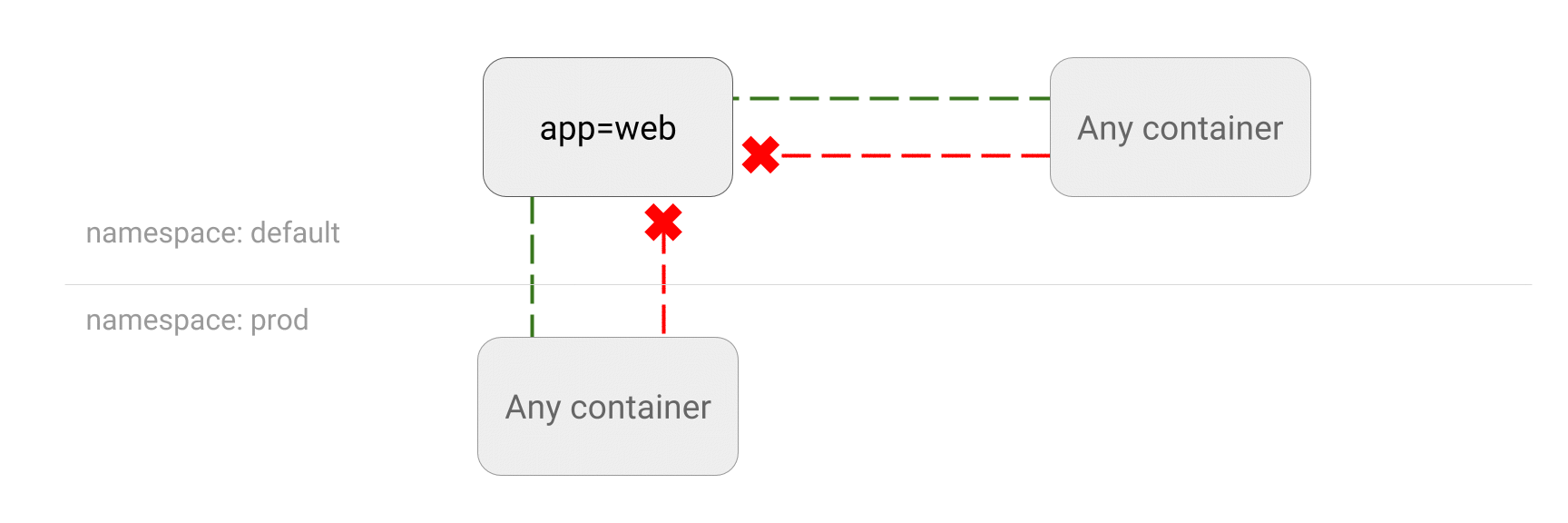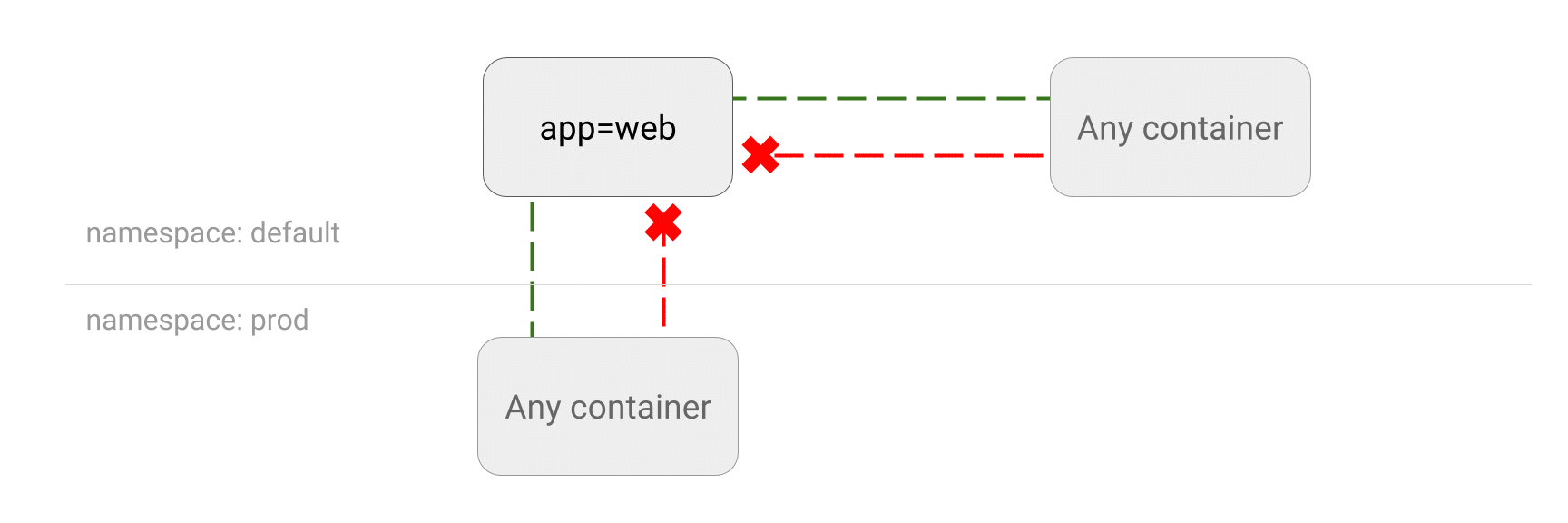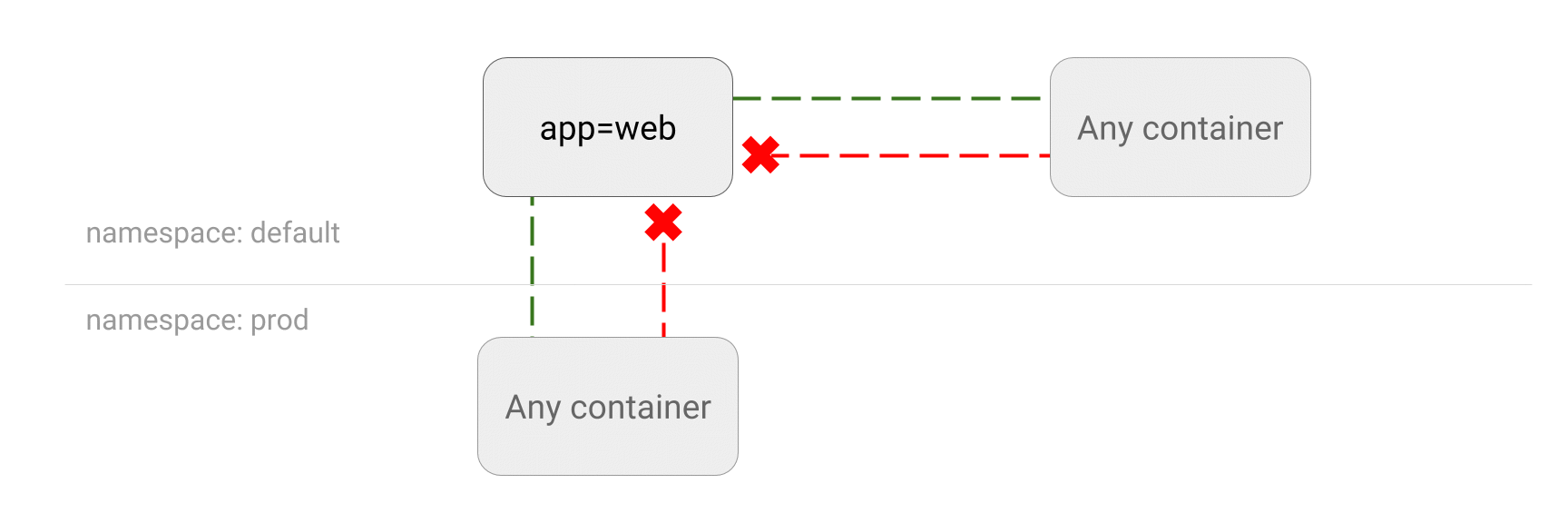 Crédits Ahmet Alp Balkan
Crédits Ahmet Alp Balkan
Par défaut, les pods ne sont pas isolés au niveau réseau : ils acceptent le trafic de n’importe quelle source.
Les pods deviennent isolés en ayant une NetworkPolicy qui les sélectionne. Une fois qu’une NetworkPolicy (dans un certain namespace) inclut un pod particulier, ce pod rejettera toutes les connexions qui ne sont pas autorisées par cette NetworkPolicy.
Le loadbalancing permet de balancer le trafic à travers plusieurs nodes Kubernetes.
Pas de solution de loadbalancing par défaut :
 Crédits Ahmet Alp Balkan
Crédits Ahmet Alp Balkan
Un Ingress est un objet pour gérer le reverse proxy dans Kubernetes : il a besoin d’un ingress controller installé sur le cluster, qui agit donc au niveau du protocole HTTP et écoute sur un port (80 ou 443 généralement), pour pouvoir rediriger vers différents services (qui à leur tour redirigent vers différents ports sur les pods) selon l’URL.
Comparaison : https://medium.com/flant-com/comparing-ingress-controllers-for-kubernetes-9b397483b46b
Envoy et Istio sont des service meshes.
Documentation officielle : https://kubernetes.io/fr/docs/concepts/services-networking/service/
Kubernetes NodePort vs LoadBalancer vs Ingress? When should I use what?
Des vidéos assez complètes sur le réseau, faites par Calico :
Sur MetalLB, les autres vidéos de la chaîne sont très bien :
Ce TP va consister à créer des objets Kubernetes pour déployer une stack d’exemple : monster_stack.
Elle est composée :
Vous pouvez utiliser au choix votre environnement Cloud ou Minikube.
Lens est une interface graphique sympathique pour Kubernetes.
Elle se connecte en utilisant la configuration ~/.kube/config par défaut et nous permettra d’accéder à un dashboard bien plus agréable à utiliser.
Vous pouvez l’installer en lançant ces commandes :
sudo apt-get update; sudo apt-get install -y libxss-dev
curl -fSL https://github.com/lensapp/lens/releases/download/v4.0.6/Lens-4.0.6.AppImage -o ~/Lens.AppImage
chmod +x ~/Lens.AppImage
~/Lens.AppImage &
monsterstackLes pods sont des ensembles de conteneurs toujours gardés ensembles.
Nous voudrions déployer notre stack monster_app. Nous allons commencer par créer un pod avec seulement notre conteneur monstericon.
Créez un projet vide monster_app_k8s.
Créez le fichier de déploiement suivant:
monstericon.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: monstericon
labels:
<labels>
Ce fichier exprime un objet déploiement vide.
Ajoutez le label app: monsterstack à cet objet Deployment.
Pour le moment notre déploiement n’est pas défini car il n’a pas de section spec:.
La première étape consiste à proposer un modèle de ReplicaSet pour notre déploiement. Ajoutez à la suite (spec: doit être à la même hauteur que kind: et metadata:) :
spec:
template:
spec:
Remplissons la section spec de notre pod monstericon à partir d’un modèle de pod lançant un conteneur Nginx :
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
monstericon, et l’image de conteneur par tecpi/monster_icon:0.1, cela récupérera l’image préalablement uploadée sur le Docker Hub (à la version 0.1)Complétez le port en mettant le port de production de notre application, 9090
Les objets dans Kubernetes sont hautement dynamiques. Pour les associer et les désigner on leur associe des labels c’est-à-dire des étiquettes avec lesquelles on peut les retrouver ou les matcher précisément. C’est grâce à des labels que k8s associe les pods aux ReplicaSets. Ajoutez à la suite au même niveau que la spec du pod :
metadata:
labels:
app: monsterstack
partie: monstericon
A ce stade nous avons décrit les pods de notre déploiement avec leurs labels (un label commun à tous les objets de l’app, un label plus spécifique à la sous-partie de l’app).
Maintenant il s’agit de rajouter quelques options pour paramétrer notre déploiement (à la hauteur de template:) :
selector:
matchLabels:
app: monsterstack
partie: monstericon
strategy:
type: Recreate
Cette section indique les labels à utiliser pour repérer les pods de ce déploiement parmi les autres.
Puis est précisée la stratégie de mise à jour (rollout) des pods pour le déploiement : Recreate désigne la stratégie la plus brutale de suppression complète des pods puis de redéploiement.
Enfin, juste avant la ligne selector: et à la hauteur du mot-clé strategy:, ajouter replicas: 3. Kubernetes crééra 3 pods identiques lors du déploiement monstericon.
Le fichier monstericon.yaml jusqu’à présent :
apiVersion: apps/v1
kind: Deployment
metadata:
name: monstericon
labels:
app: monsterstack
spec:
template:
spec:
containers:
- name: monstericon
image: tecpi/monster_icon:0.1
ports:
- containerPort: 9090
metadata:
labels:
app: monsterstack
partie: monstericon
selector:
matchLabels:
app: monsterstack
partie: monstericon
strategy:
type: Recreate
replicas: 3
apply -f appliquez notre fichier de déploiement.kubectl get deploy -o wide.kubectl get pods --watch pour vérifier que les conteneurs tournent.readinessProbe au conteneur dans le pod avec la syntaxe suivante (le mot-clé readinessProbe doit être à la hauteur du i de image:) : readinessProbe:
failureThreshold: 5 # Reessayer 5 fois
httpGet:
path: /
port: 9090
scheme: HTTP
initialDelaySeconds: 30 # Attendre 30s avant de tester
periodSeconds: 10 # Attendre 10s entre chaque essai
timeoutSeconds: 5 # Attendre 5s la reponse
Ainsi, k8s sera capable de savoir si le conteneur fonctionne bien en appelant la route /. C’est une bonne pratique pour que Kubernetes sache quand redémarrer un pod.
image: : resources:
requests:
cpu: "100m"
memory: "50Mi"
Nos pods auront alors la garantie de disposer d’un dixième de CPU et de 50 mégaoctets de RAM.
kubectl apply -f monstericon.yaml pour appliquer.kubectl get pods --watch, observons en direct la stratégie de déploiement type: Recreatekubectl describe deployment monstericon, lisons les résultats de notre readinessProbe, ainsi que comment s’est passée la stratégie de déploiement type: Recreatemonstericon.yaml final :
apiVersion: apps/v1
kind: Deployment
metadata:
name: monstericon
labels:
app: monsterstack
spec:
template:
spec:
containers:
- name: monstericon
image: tecpi/monster_icon:0.1
ports:
- containerPort: 9090
readinessProbe:
failureThreshold: 5 # Reessayer 5 fois
httpGet:
path: /
port: 9090
scheme: HTTP
initialDelaySeconds: 30 # Attendre 30s avant de tester
periodSeconds: 10 # Attendre 10s entre chaque essai
timeoutSeconds: 5 # Attendre 5s la reponse
resources:
requests:
cpu: "100m"
memory: "50Mi"
metadata:
labels:
app: monsterstack
partie: monstericon
selector:
matchLabels:
app: monsterstack
partie: monstericon
strategy:
type: Recreate
replicas: 5
Maintenant nous allons également créer un déploiement pour dnmonster:
dnmonster.yaml et collez-y le code suivant :dnmonster.yaml :
apiVersion: apps/v1
kind: Deployment
metadata:
name: dnmonster
labels:
app: monsterstack
spec:
selector:
matchLabels:
app: monsterstack
partie: dnmonster
strategy:
type: Recreate
replicas: 5
template:
metadata:
labels:
app: monsterstack
partie: dnmonster
spec:
containers:
- image: amouat/dnmonster:1.0
name: dnmonster
ports:
- containerPort: 8080
Enfin, configurons un troisième deployment redis :
redis.yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis
labels:
app: monsterstack
spec:
selector:
matchLabels:
app: monsterstack
partie: redis
strategy:
type: Recreate
replicas: 1
template:
metadata:
labels:
app: monsterstack
partie: redis
spec:
containers:
- image: redis:latest
name: redis
ports:
- containerPort: 6379
Les services K8s sont des endpoints réseaux qui balancent le trafic automatiquement vers un ensemble de pods désignés par certains labels.
Pour créer un objet Service, utilisons le code suivant, à compléter :
apiVersion: v1
kind: Service
metadata:
name: <nom_service>
labels:
app: monsterstack
spec:
ports:
- port: <port>
selector:
app: <app_selector>
partie: <tier_selector>
type: <type>
---
Ajoutez le code suivant au début de chaque fichier déploiement. Complétez pour chaque partie de notre application :
- le nom du service et le nom de la partie par le nom de notre programme (monstericon, dnmonster et redis)
- le port par le port du service
- les selectors app et partie par ceux du ReplicaSet correspondant.
Le type sera : ClusterIP pour dnmonster et redis, car ce sont des services qui n’ont à être accédés qu’en interne, et LoadBalancer pour monstericon.
Appliquez vos trois fichiers.
kubectl get services.minikube service <nom-du-service-monstericon>.Une kustomization permet de résumer un objet contenu dans de multiples fichiers en un seul lieu pour pouvoir le lancer facilement:
Créez un dossier monster_stack pour ranger les trois fichiers:
Créez également un fichier kustomization.yaml avec à l’intérieur:
resources:
- monstericon.yaml
- dnmonster.yaml
- redis.yaml
kubectl apply -k . depuis le dossier monster_stack.Installons le contrôleur Ingress Nginx avec minikube addons enable ingress.
Il s’agit d’une implémentation de loadbalancer dynamique basée sur nginx configurée pour s’interfacer avec un cluster k8s.
Ajoutez également l’objet de configuration du loadbalancer suivant dans le fichier monster-ingress.yaml :
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: monster-ingress
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
rules:
- http:
paths:
- path: /monstericon
backend:
serviceName: monstericon
servicePort: 9090
Ajoutez ce fichier à notre kustomization.yaml
Relancez la kustomization.
Vous pouvez normalement accéder à l’application en faisant minikube service monstericon --url et en ajoutant /monstericon pour y accéder.
Le dépôt Git des solutions est accessible ici : https://github.com/Uptime-Formation/tp2_k8s_monsterstack_correction
Le stockage dans Kubernetes est fourni à travers des types de stockage appelés StorageClasses :
Quand un conteneur a besoin d’un volume, il crée une PersistentVolumeClaim : une demande de volume (persistant). Si un des objets StorageClass est en capacité de le fournir, alors un PersistentVolume est créé et lié à ce conteneur : il devient disponible en tant que volume monté dans le conteneur.
On utilise les Statefulsets pour répliquer un ensemble de pods dont l’état est important : par exemple, des pods dont le rôle est d’être une base de données, manipulant des données sur un disque.
Un objet StatefulSet représente un ensemble de pods dotés d’identités uniques et de noms d’hôtes stables. Quand on supprime un StatefulSet, par défaut les volumes liés ne sont pas supprimés.
Les StatefulSets utilisent un nom en commun suivi de numéros qui se suivent. Par exemple, un StatefulSet nommé web comporte des pods nommés web-0, web-1 et web-2. Par défaut, les pods StatefulSet sont déployés dans l’ordre et arrêtés dans l’ordre inverse (web-2, web-1 puis web-0).
En général, on utilise des StatefulSets quand on veut :
Une autre raison de répliquer un ensemble de Pods est de programmer un seul Pod sur chaque nœud du cluster. En général, la motivation pour répliquer un Pod sur chaque nœud est de faire atterrir une sorte d’agent ou de démon sur chaque nœud, et l’objet Kubernetes pour y parvenir est le DaemonSet. Par exemple pour des besoins de monitoring, ou pour configurer le réseau sur chacun des nœuds.
Étant donné les similitudes entre les DaemonSets, les StatefulSets et les Deployments, il est important de comprendre quand les utiliser.
Les jobs sont utiles pour les choses que vous ne voulez faire qu’une seule fois, comme les migrations de bases de données ou les travaux par lots. Si vous exécutez une migration en tant que Pod normal, votre tâche de migration de base de données se déroulera en boucle, en repeuplant continuellement la base de données.
Comme des jobs, mais se lance à un intervalle régulier, comme avec cron.
D’après les recommandations de développement 12factor, la configuration de nos programmes doit venir de l’environnement. L’environnement est ici Kubernetes.
Les objets ConfigMaps permettent d’injecter dans des pods des fichiers de configuration en tant que volumes.
Les Secrets se manipulent comme des objets ConfigMaps, mais sont faits pour stocker des mots de passe, des clés privées, des certificats, des tokens, ou tout autre élément de config dont la confidentialité doit être préservée. Un secret se créé avec l’API Kubernetes, puis c’est au pod de demander à y avoir accès.
Il y a 3 façons de donner un accès à un secret :
tmpfs).Pour définir qui et quelle app a accès à quel secret, on utilise les fonctionnalités dites “RBAC” de Kubernetes.
Kubernetes intègre depuis quelques versions un système de permissions fines sur les ressources et les namespaces.
Roles comme admin ou monitoring qui désignent un ensemble de permissionget, list, create, delete…)ServiceAccounts dans k8s.RoleBindings.A côté des rôles crées pour les utilisateur·ices et processus du cluster, il existe des modèles de rôles prédéfinis qui sont affichables avec :
kubectl get clusterroles
La plupart de ces rôles intégrés sont destinés au kube-system, c’est-à-dire aux processus internes du cluster.
Cependant quatre rôles génériques existent aussi par défaut :
cluster-admin fournit un accès complet à l’ensemble du cluster.admin fournit un accès complet à un espace de noms précis.edit permet à un·e utilisateur·ice de modifier des choses dans un espace de noms.view permet l’accès en lecture seule à un espace de noms.La commande kubectl auth can-i permet de déterminer selon le profil utilisé (défini dans votre kubeconfig) les permissions actuelles de l’user sur les objets Kubernetes.
Les CustomResourcesDefinition sont l’objet le plus méta de Kubernetes : inventés par Red Hat pour ses Operators, ils permettent de définir un nouveau type d’objet dans Kubernetes. Combinés à des Operators (du code d’API en Go), ils permettent d’étendre Kubernetes pour gérer de nouveaux objets qui eux-même interagissent avec des objets Kubernetes.
Exemples :
elasticsearch
Nous avons vu que dans Kubernetes la configuration de nos services / applications se fait généralement via de multiples fichiers YAML.
Il est courant de décrire un ensemble de resources dans le même fichier, séparées par ---.
Mais on pourrait préférer rassembler plusieurs fichiers dans un même dossier et les appliquer d’un coup.
Pour cela K8s propose le concept de kustomization.
Exemple:
k8s-mysql/
├── kustomization.yaml
├── mysql-deployment.yaml
└── wordpress-deployment.yaml
kustomization.yaml
secretGenerator:
- name: mysql-pass
literals:
- password=YOUR_PASSWORD
resources:
- mysql-deployment.yaml
- wordpress-deployment.yaml
On peut ensuite l’appliquer avec kubectl apply -k ./
A noter que kubectl kustomize . permet de visualiser l’ensemble des modifications avant de les appliquer (kubectl kustomize . | less pour mieux lire).
Quand on a une seule application cela reste gérable avec des kustomizations ou sans, mais dès qu’on a plusieurs environnements, applications et services, on se retrouve vite submergé·es de fichiers de centaines, voire de milliers, de lignes qui sont, de plus, assez semblables. C’est donc “trop” déclaratif, et il faut se concentrer sur les quelques propriétés que l’on souhaite créer ou modifier,
Pour pallier ce problème, il existe l’utilitaire Helm, qui produit les fichiers de déploiement que l’on souhaite.
Helm est le package manager recommandé par Kubernetes, il utilise les fonctionnalités de templating du langage Go.
Helm permet donc de déployer des applications / stacks complètes en utilisant un système de templating et de dépendances, ce qui permet d’éviter la duplication et d’avoir ainsi une arborescence cohérente pour nos fichiers de configuration.
Mais Helm propose également :
Il existe des sortes de stores d’applications Kubernetes packagées avec Helm, le plus gros d’entre eux est Kubeapps Hub, maintenu par l’entreprise Bitnami qui fournit de nombreuses Charts assez robustes.
Si vous connaissez Ansible, un chart Helm est un peu l’équivalent d’un rôle Ansible dans l’écosystème Kubernetes.
Les quelques concepts centraux de Helm :
Un package Kubernetes est appelé Chart dans Helm.
Un Chart contient un lot d’informations nécessaires pour créer une application Kubernetes :
Helm désigne une application client en ligne de commande.
Pour fonctionner sur le cluster, Helm a besoin d’installer un gestionnaire appelé Tiller : c’est le serveur qui communique avec le client Helm et l’API de Kubernetes pour gérer vos déploiements.
Lors de l’initialisation de Helm, le client installe Tiller sur un pod du cluster.
Helm utilise automatiquement votre fichier kubeconfig pour se connecter.
Voici quelques commandes de bases pour Helm :
helm repo add bitnami https://charts.bitnami.com/bitnami: ajouter un repo contenant des charts
helm search repo bitnami : rechercher un chart en particulier
helm install my-chart : permet d’installer le chart my-chart. Le nom de release est généré aléatoirement dans votre cluster Kubernetes.
helm upgrade my-release my-chart : permet de mettre à jour notre release avec une nouvelle version.
helm ls: Permet de lister les Charts installés sur votre Cluster
helm delete my-release: Permet de désinstaller la release my-release de Kubernetes
Visitons un exemple de Chart : minecraft
On constate que Helm rassemble des fichiers de descriptions d’objets k8s avec des variables (moteur de templates de Go) à l’intérieur, ce qui permet de factoriser le code et de gérer puissamment la différence entre les versions.
Helm est un gestionnaire de paquet k8s qui permet d’installer des paquets sans faire des copier-coller pénibles de YAML :
Helm ne dispense pas de maîtriser l’administration de son cluster.
Pour installer Helm sur Ubuntu, utilisez : snap install helm --classic
Suivez le Quickstart : https://helm.sh/docs/intro/quickstart/
wordpress-tp de cette application (ce chart) avec helm install --template-name wordpress-tp bitnami/wordpressNotre Wordpress est prêt. Connectez-vous-y avec les identifiants affichés (il faut passer les commandes indiquées pour récupérer le mot de passe stocké dans un secret k8sen).
Explorez les différents objets k8s créés par Helm avec Lens.
Nous allons déployer une application dans Azure à l’aide de charts Helm : https://docs.bitnami.com/kubernetes/get-started-aks/
Tout d’abord, il faut se créer un compte Azure. Si c’est la première fois, du crédit gratuit est disponible : https://azure.microsoft.com/fr-fr/free/ Ensuite on peut utiliser le Cloud Shell Azure ou n’importe quel terminal.
# Install Azure CLI
curl -sL https://aka.ms/InstallAzureCLIDeb | sudo bash
# Login
az login --allow-no-subscriptions
# Créer le groupe de ressources
az group create --name aks-resource-group --location westeurope
Au préalable, installer kubectl (pas besoin dans le Cloud Shell) :
snap install kubectl --classic
# Créer deux nœuds dans le cluster AKS
az aks create --name aks-cluster --resource-group aks-resource-group --node-count 2 --generate-ssh-keys
# Récupérer la config AKS
az aks get-credentials --name aks-cluster --resource-group aks-resource-group
Pour créer le registry, il faut choisir un nom unique, remplacez pommedeterrepoirekiwi par un autre nom.
# Créer le registry
az acr create --resource-group aks-resource-group --name pommedeterrepoirekiwi --sku Basic
az acr login --name pommedeterrepoirekiwi
# Créer un compte sur le registry pour K8S
ACR_LOGIN_SERVER=$(az acr show --name pommedeterrepoirekiwi --query loginServer --output tsv)
ACR_REGISTRY_ID=$(az acr show --name pommedeterrepoirekiwi --query id --output tsv)
SP_PASSWD=$(az ad sp create-for-rbac --name k8s-read-registry --role Reader --scopes $ACR_REGISTRY_ID --query password --output tsv)
CLIENT_ID=$(az ad sp show --id http://k8s-read-registry --query appId --output tsv)
kubectl create secret docker-registry read-registry-account \
--docker-server $ACR_LOGIN_SERVER \
--docker-username $CLIENT_ID \
--docker-password $SP_PASSWD \
--docker-email cto@example.org
Pour installer Docker : curl -sSL https://get.docker.com | sudo sh
# Récupérer puis pousser une image sur son registry Azure
docker pull docker.io/bitnami/wordpress:latest
docker tag docker.io/bitnami/wordpress:latest pommedeterrepoirekiwi.azurecr.io/bitnami/wordpress:latest
docker push pommedeterrepoirekiwi.azurecr.io/bitnami/wordpress:latest
Pour installer Helm : curl https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3 | bash
# Ajout de la chart
helm repo add bitnami https://charts.bitnami.com/bitnami
# Installer la chart
helm install wordpress bitnami/wordpress \
--set serviceType=LoadBalancer \
--set image.registry="pommedeterrepoirekiwi.azurecr.io" \
--set image.pullSecrets={read-registry-account} \
--set image.repository=bitnami/wordpress \
--set image.tag=latest
Des messages s’affichent suite à l’application de la chart Helm, suivez les instructions pour accéder au Wordpress.
Terraform est un outil permettant de décrire des ressources cloud dans un fichier pour utiliser le concept d’infrastructure-as-code avec tous les objets des fournisseurs de Cloud.
https://registry.terraform.io/providers/hashicorp/azurerm/latest/docs/resources/kubernetes_cluster
https://github.com/terraform-providers/terraform-provider-azurerm/tree/master/examples/kubernetes
https://registry.terraform.io/modules/Azure/appgw-ingress-k8s-cluster/azurerm/latest
https://docs.microsoft.com/fr-fr/azure/aks/ingress-basic#create-an-ingress-controller
Vidéo “K8s Networking in Azure” : https://www.youtube.com/watch?v=JyLtg_SJ1lo&list=PLoWxE_5hnZUZMWrEON3wxMBoIZvweGeiq&index=2
https://docs.microsoft.com/fr-fr/azure/aks/load-balancer-standard
https://docs.microsoft.com/fr-fr/azure/aks/http-application-routing
https://blog.crossplane.io/azure-secure-connectivity-for-aks-azure-db/
https://github.com/Azure/azure-service-operator
En lançant la chart PostgreSQL HA de Bitnami, et en lisant les logs des conteneurs, observez comment fonctionne les StatefulSets, par exemple avec Lens. Scalez les StatefulSets postgres.
https://kubernetes.io/docs/tasks/access-application-cluster/ingress-minikube/
https://docs.microsoft.com/fr-fr/azure/aks/ingress-basic
Pour les DNS, 3 solutions :
/etc/hostsnetlib.reminikube start --extra-config=apiserver.Authorization.Mode=RBAC
kubectl create clusterrolebinding add-on-cluster-admin --clusterrole=cluster-admin --serviceaccount=kube-system:default
~/.kube/config :cluster-admin,rolebindingkubectl auth can-i pour différents cas et observer la différenceUne difficulté à manier tout ce qui est stateful, comme des bases de données
Beaucoup de points sont laissés à la décision du fournisseur de cloud ou des admins système :
Pas de solution de stockage par défaut, et parfois difficile de stocker “simplement” sans passer par les fournisseurs de cloud, ou par une solution de stockage décentralisé à part entière (Ceph, Gluster, Longhorn…)
Beaucoup de solutions de réseau qui se concurrencent, demandant un comparatif fastidieux
Pas de solution de loadbalancing par défaut : soit on se base sur le fournisseur de cloud, soit on configure MetalLB –>
Avec Prometheus et la suite Elastic.
git pullkubectl applyLa Bitnami Kubernetes Production Runtime (BKPR).
Pour comprendre les stratégies de déploiement et mise à jour d’application dans Kubernetes (deployment and rollout strategies) nous allons installer puis mettre à jour une application d’exemple et observer comment sont gérées les requêtes vers notre application en fonction de la stratégie de déploiement choisie.
Pour cette observation on peut utiliser un outil de monitoring. Nous utiliserons ce TP comme prétexte pour installer une des stack les plus populaires et intégrée avec kubernetes : Prometheus et Grafana. Prometheus est un projet de la Cloud Native Computing Foundation.
Prometheus est un serveur de métriques c’est à dire qu’il enregistre des informations précises (de petite taille) sur différents aspects d’un système informatique et ce de façon périodique en effectuant généralement des requêtes vers les composants du système (metrics scraping).
Installez Helm si ce n’est pas déjà fait. Sur Ubuntu : sudo snap install helm --classic
Créons un namespace pour prometheus et grafana : kubectl create namespace monitoring
Ajoutez le dépot de chart Prometheus et kube-state-metrics: helm repo add prometheus-community https://prometheus-community.github.io/helm-charts puis helm repo add kube-state-metrics https://kubernetes.github.io/kube-state-metrics puis mise à jours des dépots helm helm repo update.
Installez ensuite le chart prometheus :
helm install \
--namespace=monitoring \
--version=13.2.1 \
--set=service.type=NodePort \
prometheus \
prometheus-community/prometheus
Le chart officiel installe par défaut en plus de Prometheus, kube-state-metrics qui est une intégration automatique de kubernetes et prometheus.
Une fois le chart installé vous pouvez visualisez les informations dans Lens, dans la premiere section du menu de gauche Cluster.
Nous allons installer une petite application d’exemple en go.
git clone https://github.com/e-lie/k8s-deployment-strategiesNous allons d’abord construire l’image docker de l’application à partir des sources. Cette image doit être stockée dans le registry de minikube pour pouvoir être ensuite déployée dans le cluster. En mode développement Minikube s’interface de façon très fluide avec la ligne de commande Docker grace à quelques variable d’environnement : minikube docker-env
eval et la commande précédente.goprom_app et “construisez” l’image docker de l’application avec le tag uptime-formation/goprom.Allez dans le dossier de la première stratégie recreate et ouvrez le fichier app-v1.yml. Notez que image: est à uptime-formation/goprom et qu’un paramètre imagePullPolicy est défini à Never. Ainsi l’image sera récupéré dans le registry local du docker de minikube ou sont stockées les images buildées localement plutôt que récupéré depuis un registry distant.
Appliquez ce déploiement kubernetes:
main.go ainsi que le fichier de déploiement app-v1.yml. Quelles sont les routes http exposées par l’application ?Minikube pour accéder au service goprom dans votre navigateur.goprom-metrics dans votre navigateur. Quelles informations récupère-t-on sur cette route ?Pour tester le service prometheus-server nous avons besoin de le mettre en mode NodePort (et non ClusterIP par défaut). Modifiez le service dans Lens pour changer son type.
Exposez le service avec Minikube (n’oubliez pas de préciser le namespace monitoring).
Vérifiez que prometheus récupère bien les métriques de l’application avec la requête PromQL : sum(rate(http_requests_total{app="goprom"}[5m])) by (version).
Quelle est la section des fichiers de déploiement qui indique à prometheus ou récupérer les métriques ?
Grafana est une interface de dashboard de monitoring facilement intégrable avec Prometheus. Elle va nous permettre d’afficher un histogramme en temps réel du nombre de requêtes vers l’application.
Créez un secret Kubernetes pour stocker le loging admin de grafana.
cat <<EOF | kubectl apply -n monitoring -f -
apiVersion: v1
kind: Secret
metadata:
namespace: monitoring
name: grafana-auth
type: Opaque
data:
admin-user: $(echo -n "admin" | base64 -w0)
admin-password: $(echo -n "admin" | base64 -w0)
EOF
Ensuite, installez le chart Grafana en précisant quelques paramètres:
helm repo add grafana https://grafana.github.io/helm-charts
helm repo update
helm install \
--namespace=monitoring \
--version=6.1.17 \
--set=admin.existingSecret=grafana-auth \
--set=service.type=NodePort \
--set=service.nodePort=32001 \
grafana \
grafana/grafana
Maintenant Grafana est installé vous pouvez y acccéder en forwardant le port du service grace à Minikube:
$ minikube service grafana
Pour vous connectez utilisez, username: admin, password: admin.
Il faut ensuite connecter Grafana à Prometheus, pour ce faire ajoutez une DataSource:
Name: prometheus
Type: Prometheus
Url: http://prometheus-server
Access: Server
Créer une dashboard avec un Graphe. Utilisez la requête prometheus (champ query suivante):
sum(rate(http_requests_total{app="goprom"}[5m])) by (version)
Pour avoir un meilleur aperçu de la version de l’application accédée au fur et à mesure du déploiement, ajoutez {{version}} dans le champ legend.
Ce TP est basé sur l’article suivant: https://blog.container-solutions.com/kubernetes-deployment-strategies
Maintenant que l’environnement a été configuré :
README.md.app-v1.yml pour une stratégie.service=$(minikube service goprom --url) ; while sleep 0.1; do curl "$service"; doneapp-v2.yml correspondant.graphana (Il faut configurer correctement le graphique pour observer de façon lisible la transition entre v1 et v2). Un aperçu en image des histogrammes du nombre de requêtes en fonction des versions 1 et 2 est disponible dans chaque dossier de stratégie.delete -f ou dans Lens.Par exemple pour la stratégie recreate le graphique donne: 
Pour exporter correctement les TPs et autres pages de ce site au format pdf, utilisez la fonction imprimer de Google Chrome ou Firefox (vous pouvez aussi activer le Mode Lecture de Firefox en cliquant Affichage > Passer en Mode Lecture) en ouvrant la page suivante :
Vous trouverez ici quelques tutoriels qui peuvent être utiles dans le cadre des formations.
Bien éteindre la machine.
Sur le système hôte (Windows ou Linux):
gparted : lien sourceforgePour redimensionner le disque sur Windows:
C:\Users\<votre_user>\Virtualbox VMs\<votre_machine>\# la première ligne est utile seulement si le disque est au format vdmk
"C:\Program Files\Oracle\VirtualBox\VBoxManage" clonemedium "<votre_disque>.vmdk" "<votre_disque>.vdi" --format vdi
"C:\Program Files\Oracle\VirtualBox\VBoxManage" modifymedium "cloned.vdi" --resize 20480
"~/Virtualbox VMs", entrez dans le dossier de la machine en question.# la première ligne est utile seulement si le disque est au format vdmk
VBoxManage clonemedium "<votre_disque>.vmdk" "<votre_disque>.vdi" --format vdi
VBoxManage modifymedium "cloned.vdi" --resize 20480 # 20Gio par exemple.
Allez dans la configuration de la machine, déconnectez le disque VMDK et connectez le nouveau disque VDI.
Ajoutez le CD gparted à la machine.
Lancez la machine.
Gparted demarre. choisissez le type de clavier (fr) puis le lancement avec serveur X (option 0).
Une fenêtre avec votre disque s’affiche. Cliquez sur le disque dans la liste puis “redimensionner/déplacer”
Dans la fenêtre suivante, agrandissez à la souris la partition pour occuper tout l’espace disponible.
Faites ok puis appliquer.
Documentation officielle : https://kubernetes.io/fr/docs/concepts/services-networking/service/
Kubernetes NodePort vs LoadBalancer vs Ingress? When should I use what?
Comparatif de solutions réseaux (fr) : https://www.objectif-libre.com/fr/blog/2018/07/05/comparatif-solutions-reseaux-kubernetes/#Flannel
Comparatif de solutions réseaux (en) :https://rancher.com/blog/2019/2019-03-21-comparing-kubernetes-cni-providers-flannel-calico-canal-and-weave/
Des vidéos assez complètes sur le réseau, faites par Calico :
Sur MetalLB, les autres vidéos de la chaîne sont très bien :
Vidéo “K8s Networking in Azure” : https://www.youtube.com/watch?v=JyLtg_SJ1lo&list=PLoWxE_5hnZUZMWrEON3wxMBoIZvweGeiq&index=2
https://docs.microsoft.com/fr-fr/azure/aks/load-balancer-standard
https://docs.microsoft.com/fr-fr/azure/aks/http-application-routing
https://blog.crossplane.io/azure-secure-connectivity-for-aks-azure-db/
Terraform est un outil permettant de décrire des ressources cloud dans un fichier pour utiliser le concept d’infrastructure-as-code avec tous les objets des fournisseurs de Cloud.
https://registry.terraform.io/providers/hashicorp/azurerm/latest/docs/resources/kubernetes_cluster
https://github.com/terraform-providers/terraform-provider-azurerm/tree/master/examples/kubernetes
https://registry.terraform.io/modules/Azure/appgw-ingress-k8s-cluster/azurerm/latest
https://docs.microsoft.com/fr-fr/azure/aks/ingress-basic#create-an-ingress-controller